




近年来,应用场景的旺盛需求,推动AI领域将技术能力从感知延伸到认知、从2D扩展到3D。
3月19日,云从科技基于单帧图像的3D人体重建技术同时在Human3.6M、Surreal和UP-3D上创造了最新的世界纪录,此次突破将原有最低误差记录大幅降低30%,也是继去年云从在3D人脸数据集上大幅刷新纪录后,再次在此类3D重建技术上取得重要成果。
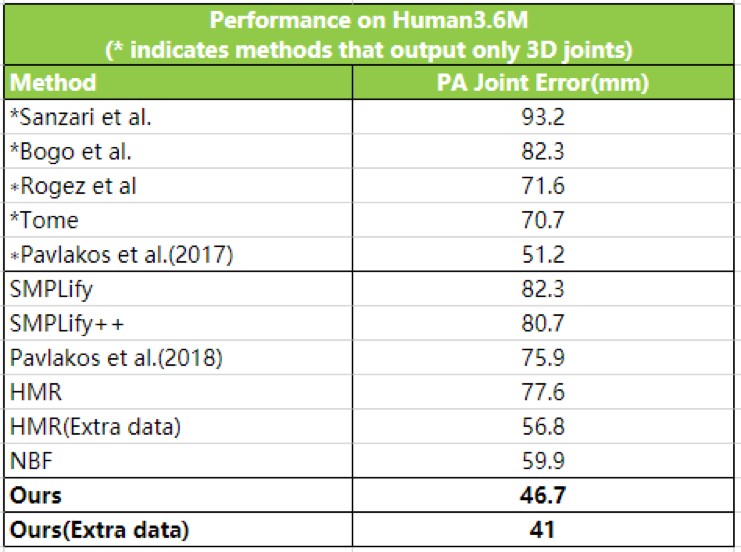
Human3.6M数据集上对比
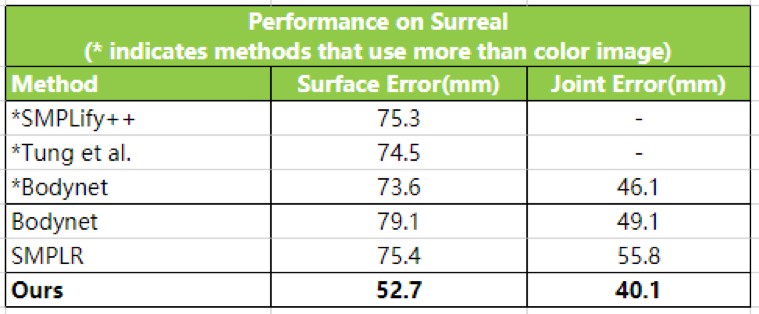
Surreal数据集上对比
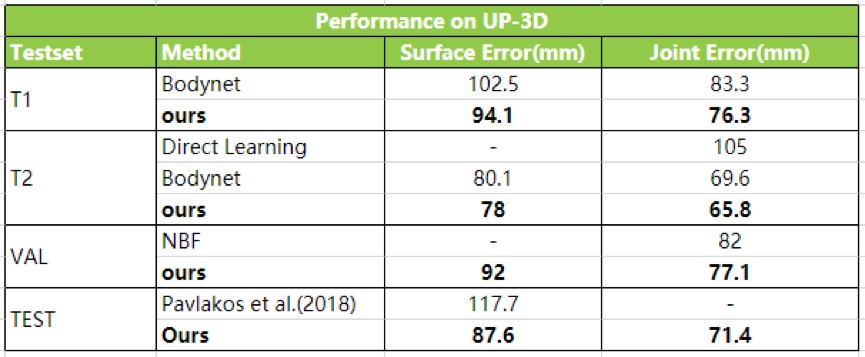
UP-3D数据集上对比
3D重建领域通常以误差(Error)作为衡量算法能力的主要指标,误差(Error)就是生成模型与实际图像的差别。一般来说,误差(Error)越低,精度越高,意味着技术的性能越好。
云从科技3D人体重建技术全身精度误差(Surface Error)在Surreal上从75.4毫米降低到52.7毫米,关节精度误差(3D Joint Error)从55.8毫米降低到40.1毫米,Human3.6M上的关节精度误差(3D Joint Error)从59.9毫米降低到46.7毫米,技术的执行速度从之前的上百毫秒降低到仅需5毫秒。
论文中,云从科技针对人体具有丰富多样的姿态和穿着的特点,提出了一套全新的基于人体3D纵深预测的3D信息表征方式。通过对三原色图像(RGB,不含深度信息)的分析,预测人体的3D形态和姿势,并用6万多个点完整描绘人体,从而在人体重建技术上取得速度与精度的双突破,呈现出来的模型更精细,帧率更是高达到200fps,原本由于受实时显示限制而无法实现的应用可以一一实现——这将极大地推动相关智能图像应用的落地步伐。

由于对输入图像的要求低,使3D重建技术将可以利用普通光学摄像头作为感知设备。该技术将会使美颜APP无需结构光摄像头也能具备高精准度的瘦身与动画合成功能;商场内试衣魔镜将会自动根据身形生成你所想要更换的衣服,大大节省商场空间的同时提升用户体验度,使更多智能应用成为可能。
通过重要人员影像重建、医疗仿真肢体打印、虚拟试衣、美颜化妆、表情姿态动画合成等应用场景在大型商场、直播平台、美颜软件、影视特效制作等行业普惠AI能力。
值得一提的是,Human3.6M、Surreal和UP-3D是全球关于3D人体重建技术的权威数据集,加州大学伯克利分校、马克斯-普朗克研究所、Amazon、宾夕法尼亚大学、北京大学、浙江大学、Microsoft Research、法国国家信息与自动化研究所、Adobe Research等知名企业、研究所和大学都在该榜单的竞争队列中,算法实力比拼可谓激烈,相较于以往,中国企业与高校机构开始逐渐在国外老牌优势领域展露头角。
与传统关键点检测、3D重建技术的区别
传统的人体关键点检测技术往往以2D的人体骨骼关节点检测形式出现,即通过技术预测RGB图像中人体的十几个关节点的坐标,一方面结果非常稀疏,将人体大为简化成骨骼的形式,另一方面结果往往只包含二维平面上的坐标预测,不能还原深度信息,因此无法体现纵深的感觉。而基于单帧图像的3D重建技术不仅能输出骨骼关节点信息,更能同时预测大量的人体表面关键点信息,预测结果更加丰富,而且每个点的坐标都是3D的,能够体现不同躯干的纵深信息。

3D关键点检测
并且传统3D重建技术大多需要连续的图像序列或是多视角的图像,在硬件设备上一般需要采用双目摄像机或者结构光摄像机等设备,因此在手机等便携设备上往往难以实现;另一方面,专用设备还会增加部署成本,增加大规模普及3D重建技术的难度。

基于单帧图像的3D重建技术对原始图像的需求放松的同时,对背后的技术提出了更难的挑战:技术需要从单帧图像中推理出人体或人脸的3D形态,并通过【光学透视】【阴影叠加】等基本光学原则准确预测出各个关键点在3D空间的位置和朝向,从而得到人体的姿态或表情信息。

人体姿态和服饰复杂多样,精度提升意味着对复杂场景的适应性更好,模型更接近真实的情况。如阿凡达、漫威电影、阿丽塔等电影中,都需要专用特效设备与面部贴点来完成精细的人像采集,基于单帧图像的3D人体/人脸重建技术将彻底颠覆电影视频的拍摄制作,同时降低工业级3D动画合成的门槛。





