





编者按:本文来自微信公众号 阿尔法公社(ID:alphastartups),创业邦经授权转载,头图来源摄图网
阿尔法公社创始合伙人许四清:向量数据库最早被研究人员用向量空间模型做存储和查询,其高效、灵活支持多模态、可分布式存储,尤其是很好地支持并行计算等特征,成为生成式人工智能不可或缺的支撑。熟悉向量数据库的大厂技术人员,面对极好的创业窗口,欢迎大家一起研究这个领域的机会。
ChatGPT的横空出世,带动了新一波生成式AI的创业浪潮。据统计,ChatGPT3.5出现以后,4个月左右的时间内,美国在人工智能领域发生了近500笔投资,总投资金额近160亿美元,平均每个项目超过3000万美元。
阿尔法公社创始合伙人许四清认为:“在这一轮生成式AI的创业竞争比赛里,‘得人才者得模型,得模型者得天下’。一个比较大的创业机会是在基础模型底座和垂直应用结合,也就是得模型者得天下——懂模型的人利用模型,在大语言模型和技术基础之上做模型的创新级应用。”
但大语言模型目前的一个通病是,它会“一本正经的胡说八道”,也就是产生“幻觉”,这限制了它在垂直领域的实用性。虽然此前OpenAI首席科学家Ilya Sutskever表示可以通过“人类反馈强化学习”(RLHF)来让模型对错误的输出结果进行调整,但这种方法并不能彻底解决大语言模型的“幻觉”问题。
相比RLHF,向量嵌入(vector embeddings)可能是一种更靠谱的方法。通过为大语言模型创建一个向量数据库,把来源权威,可信的非结构化数据转换成向量,并储存到数据库中,就能帮助大语言模型具有“长期记忆”,并且减少它产生“幻觉”的可能性。
面对这个机会,有远见和敏感性的非凡创业者们不会错过,就在过去一个月内,连续三家致力于向量数据库的创业公司获得融资,我们将在本文为大家理清向量数据库到底怎么解决大模型的“幻觉”问题,以及我们欣赏的AlphaFounders又如何在这个新兴赛道上“各显神通”。
向量数据库,助力解决大模型的“幻觉”问题
Vector database(向量数据库),也称为向量相似度搜索引擎或近似最近邻(ANN)搜索数据库,是一种专门用来处理向量嵌入的数据库。它通过比较值并找到彼此相似的值来索引向量,以便于搜索和检索。与其他传统数据库不同,它能够处理复杂数据,如文档、图像、视频和网页上的纯文本等非结构化数据,使人们(和系统)能够搜索未标记的内容,这对于扩展大语言模型(LLM),比如ChatGPT所使用的GPT-4的用例尤为重要。
向量数据库简化了人工智能开发者对向量数据的管理。作为必不可少的AI原生基础设施组件,通过把来源权威,可信的图片、视频和文本这样的非结构化数据转换成向量,并储存到向量数据库中,它就能帮助大模型具有“长期记忆”,并且减少大模型产生“幻觉”的可能性。
根据Gartner的数据,非结构化数据占企业生成的新数据比例高达90%,并且增长速度比结构化数据快三倍。与此同时,绝大多数人工智能研发项目从未投入生产,向量数据库领域创业公司Qdrant的CEO兼联合创始人Andre Zayarni认为这是因为缺乏正确的工具——最终,将大模型连接到实时的非结构化数据可以为任何希望构建更有用AI应用的人打开大量机会。
一个月内,3家向量数据库创业公司获得新融资
Chroma获得1800万美元种子轮融资
Chroma由Jeff Huber和Anton Troynikov共同创建,Jeff是连续创业者,入选福布斯30 Under 30精英榜,他的上一家企业获得了YC投资,做的是低成本的假肢制造。Anton Troynikov也是连续创业者,同时长期担任过Nuro和Meta的计算机视觉工程师。
作为向量数据库研发商,Chroma的主要产品是开源的嵌入式向量数据库。Chroma认为大模型浪潮催生了新的计算堆栈,这个新的堆栈包括:
LLM应用逻辑:Langchain、Llamaindex-使开发者能够围绕他们的用例编写业务逻辑
LLM/嵌入提供商:OpenAI、Anthropic、Cohere-原始的CPU/马力
嵌入式数据库:Chroma-使大模型应用程序具有长期记忆。
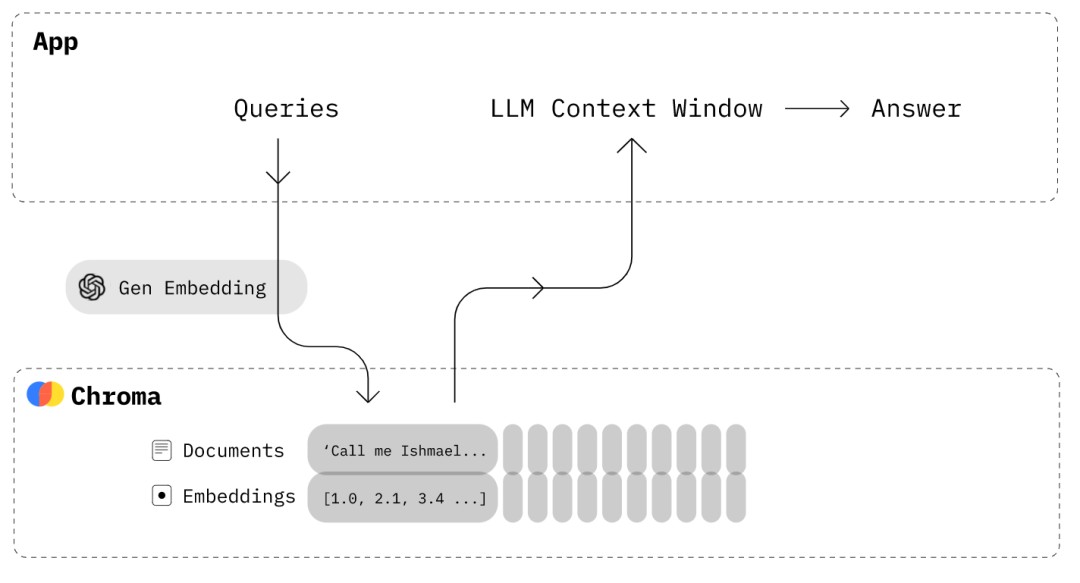
很多AI领域的开发者表示他们希望能够“使用自己的数据”做出ChatGPT式的产品,Chroma的数据库通过基于嵌入式文档检索提供了这种“使用自己的数据”的桥梁。
近日,Chroma获得由Quiet Capital领投的1800万美元种子轮融资。除了机构投资者外,他们还获得了MongoDB、Scale、Hugging Face、Jasper等公司创始人或高管的投资,受到了整个生成式AI生态的欢迎。
Weaviate获得5000万美元B轮融资
Weaviate同样是AI原生向量数据库研发商,它的数据库可以存储高达数十亿个向量,还使处理这些向量更加容易。
Bob van Luijt是一个复合背景的连续创业者,15岁开始编写软件,却又有伯克利音乐学院和哈佛商学院的学习经历。他创立IT公司Kubrickology Innovations B.V,之后与Etienne Dilocker共同创立Weaviate,两人分别担任CEO和CTO。这两位创业者看似没有光鲜的大公司经历,但是他们都有10年以上的自由工程师经历,具有深厚的技术积累。
Weaviate的AI原生向量数据库的功能包括:
可扩展的内置机器学习模块——只需加载并搜索;Weaviate完成ML的繁重工作——任何数据类型、任何模型、任何用例。
更丰富的向量搜索——支持各种ML搜索,并且可以搜索向量以及生成向量的源对象。
高性能——亚秒级搜索,可扩展到数十亿个对象,无间断运行。

对于垂直领域的创业者,使用向量数据库,可以让他们仅对与模型连接的向量数据库中存储的内容进行小型和定期更新,以使模型意识到新信息,并减少需要重复训练大语言模型和频繁更新的需求,这样即使在耗时的重新训练权重更新之间,大模型也能提供强大而最新的定制答案。
Weaviate在今年早些时候推出了ChatGPT的Plug in插件,该插件的主要功能包括:
允许用户连接一个向量数据库到ChatGPT,其中包含专有数据,可以被ChatGPT用于回答非常具体的问题。
允许用户持久化个人文档和细节,使ChatGPT带有个性化特色,因此答案不仅仅是一般性的,还可以根据向量数据库中指定的细节为用户量身定制。
用户可以在连接的向量数据库中持久化与ChatGPT的对话,以在打开和关闭ChatGPT标签之间继续对话。
简而言之,使用此插件,用户可以让ChatGPT“了解”自己的自定义数据,并大幅度提高回答问题的质量。不仅如此,向量数据库还可以用作ChatGPT的长期记忆存储,原本ChatGPT可以在一次“聊天”中记住用户的上下文,并提供反馈,而拥有“长期记忆”后,哪怕用户关闭了某一次“聊天”,当他在新“聊天”中再一次提起相关话题时,ChatGPT也能接着上一次的话题继续很好的给出回答。

自2022年初获得A轮融资以来,Weaviate本月又获得一轮5000万美元的B轮融资,这轮融资由Index Ventures领投,参与投资的还包括Battery Ventures、NEA、Cortical Ventures、Zetta Venture Partners等知名机构。目前,Weaviate总共获得6770万美元的外部融资。
开源向量数据库初创公司Qdrant获750万美元种子融资
Qdrant成立于2021年,它针对人工智能软件开发人员,提供用于非结构化数据的开源向量搜索引擎和数据库。
Qdrant的两位创始人Andre Zayarni(CEO)和Andrey Vasnetsov(CTO)是老同事,他们在共同创立Qdrant之前,都在智能招聘公司moberries工作,Andre Zayarni是CTO,Andrey Vasnetsov是Lead Data Scientist。两位创始人在moberries工作之前,也均具有较为深厚的技术背景和经验,在多家欧洲的科技公司领导过技术团队。
Qdrant认为向量数据库已成为新人工智能技术堆栈的基本构建块。它们使开发人员通过实时和真实世界的数据来扩展ChatGPT等基于大语言模型的应用程序的“知识库”,从而构建更先进的应用程序。
Qdrant对近似最近邻搜索(ANN)算法HNSW进行了独特的定制修改,允许以最先进的速度查询结果并应用过滤器,而不会影响结果。云原生支持分布式部署和复制,使引擎适用于具有实时延迟要求的高吞吐量应用程序。

Qdrant近期获得750万美元的种子轮融资,领投方为Unusual Ventures,42cap、IBB Ventures以及包括Cloudera联合创始人Amr Awadallah在内的个人天使投资人。
OpenAI合作者Pinecone累计融资3800万美元
除了在本月获得融资的三家向量数据库创业公司外,我们额外介绍一家在2022年获得A轮融资的公司——Pinecone。
Pinecone由Edo Liberty创立,他本科毕业于特拉维夫大学,在耶鲁获得计算机科学的PHD。在创立Pinecone之前, Liberty是亚马逊AI实验室的领导者,并在AWS构建了SageMaker机器学习平台和服务,根据谷歌学术,他的论文引用数高达4326,是一位兼具学术视野和工程经验的非凡创业者。
Pinecone是向量数据库领域的早期探索者之一,目前非常火的AutoGPT就集成了它的产品。Pinecone也是OpenAI的合作方,用户可以通过OpenAI的Embedding API生成语言嵌入,然后在Pinecone中为这些嵌入建立索引,以实现快速且可扩展的向量搜索。
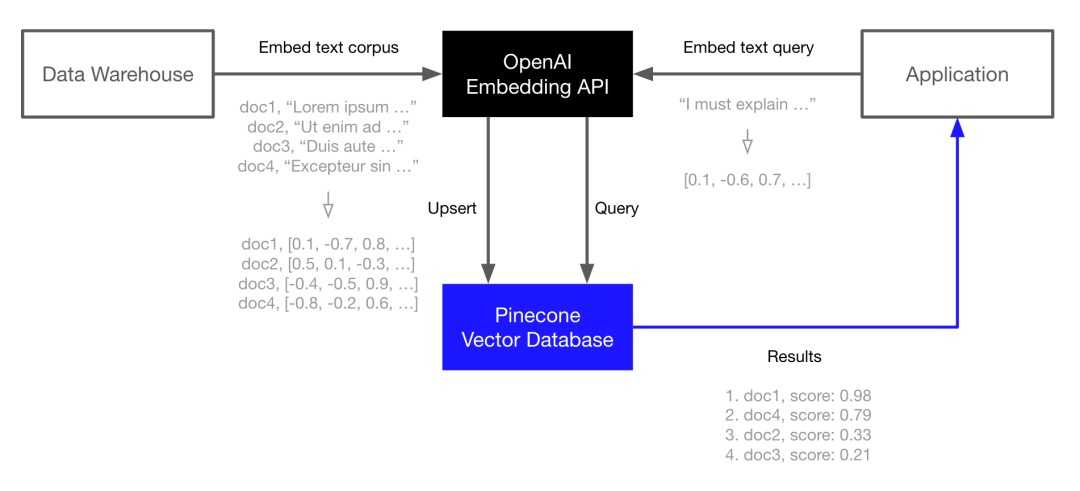
Pinecone在2021年1月获得Wing Venture Capital 领投的1000万美元种子投资,在2022年3月底,又获得Menlo Ventures领投的2800万美元A轮融资,其他投资者还包括Tiger Global和前Snowflake CEO Bob Muglia等个人投资人。目前它的总融资额达到3800万美元。
生成式AI催生底层技术变革,向量数据库大有可为
每一次表层应用需求的转变,都会推动底层基础设施技术的更新。本次生成式AI的创新,来自于拥有超大数据量的大语言模型,而训练用的数据又是非结构化的,数据类型的变化和数据量的变化,催生了向量数据库的需求,而生成式AI创业的蓬勃之势,显示这个需求必然是巨大的。
生成式AI的发展可谓日新月异,而大公司的创新速度大概率比不上创业公司,这次生成式AI的爆发由OpenAI而不是Google引发,就证明了这一点。同理,向量数据库的发展机会很可能不在大公司,而在创业公司。
生成式AI的创业在中国同样大有可为,我们也相信向量数据库在中国有很好的创业机会,期待与有志于向量数据库方向的创业者多交流。
本文为创业邦原创,未经授权不得转载,否则创业邦将保留向其追究法律责任的权利。如需转载或有任何疑问,请联系editor@cyzone.cn。





