编者按:本文来自微信公众号 新智元(ID:AI_era),编辑:Aeneas 好困,创业邦经授权转载
最近,大名鼎鼎的Stable Diffusion背后的公司,一连整了两个大活。
首先,Stability AI重磅发布了世上首个基于RLHF的开源LLM聊天机器人——StableVicuna。

StableVicuna基于Vicuna-13B模型实现,是第一个使用人类反馈训练的大规模开源聊天机器人。
有网友经过实测后表示,StableVicuna就是目前当之无愧的13B LLM之王!
对此,1x exited创始人表示,这可以看作是自ChatGPT推出以来的第二个里程碑。
另外,Stability AI 发布了开源模型DeepFloyd IF,这个文本到图像的级联像素扩散模型功能超强,可以巧妙地把文本集成到图像中。

这个模型的革命性意义在于,它一连解决了文生图领域的两大难题:正确生成文字,正确理解空间关系!
秉持着开源的一贯传统,DeepFloyd IF在以后会完全开源。
Stailibity AI,果然是开源界当之无愧的扛把子。
StableVicuna
世上首个开源RLHF LLM聊天机器人StableVicuna,由Stability AI震撼发布!

一位Youtube主播对Stable Vicuna进行了实测,Stable Vicuna在每一次测试中,都击败了前任王者Vicuna。

所以这位Youtuber激动地喊出:Stable Vicuna就是目前最强大的 13B LLM模型,是当之无愧的LLM模型之王!

StableVicuna基于小羊驼Vicuna-13B模型实现, 是Vicuna-13B的进一步指令微调和RLHF训练的版本。
而Vicuna-13B是LLaMA-13B的一个指令微调模型。

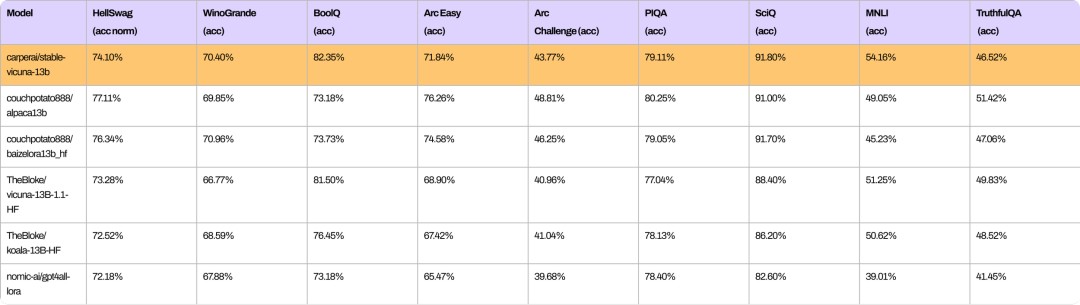
从以下基准测试可以看出,StableVicuna与类似规模的开源聊天机器人在整体性能上的比较。
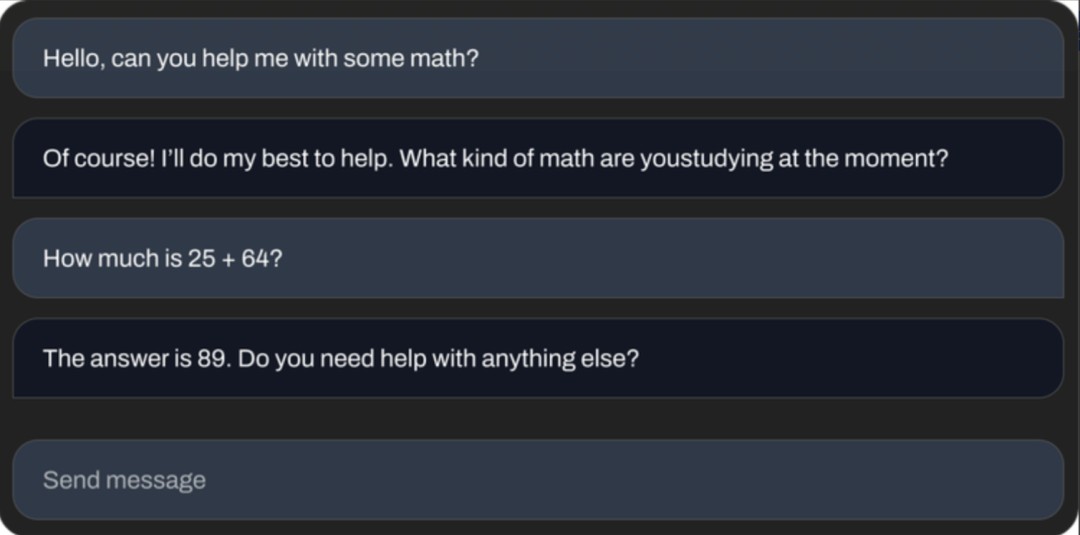
StableVicuna可以做基础数学题。
可以写代码。
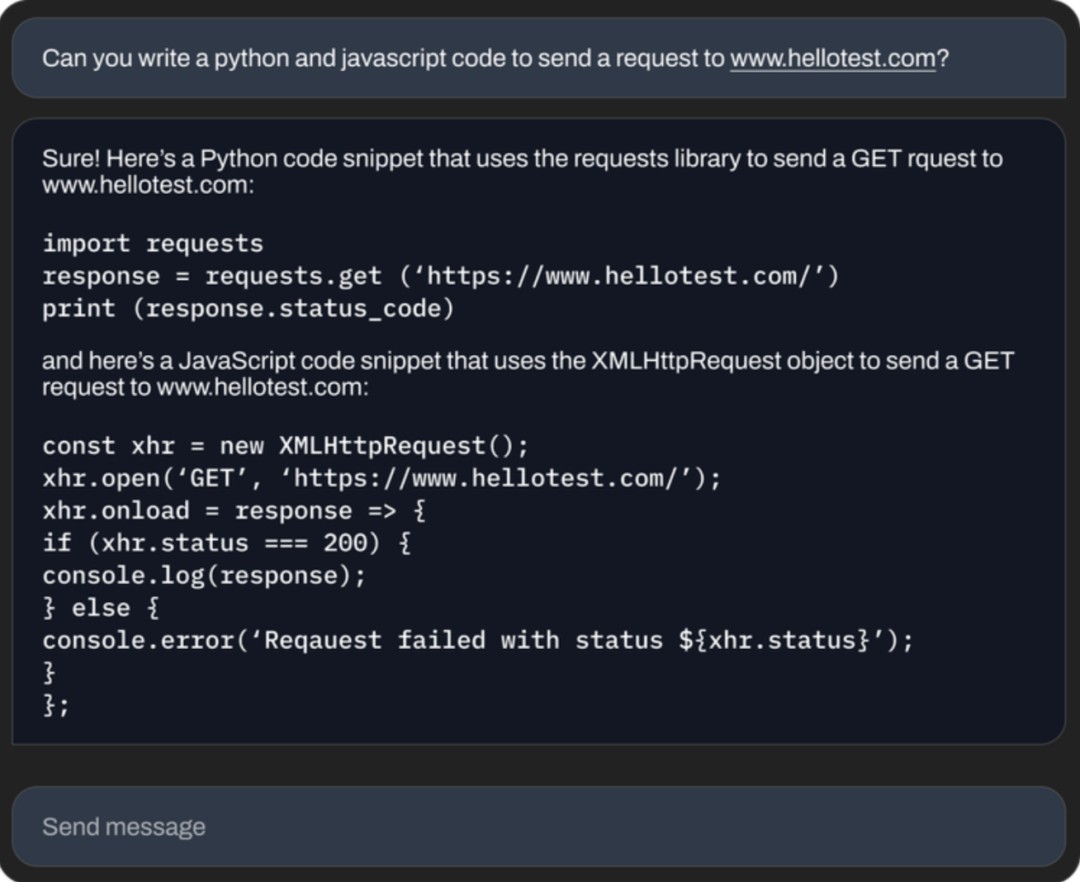
还能为你讲解语法知识。
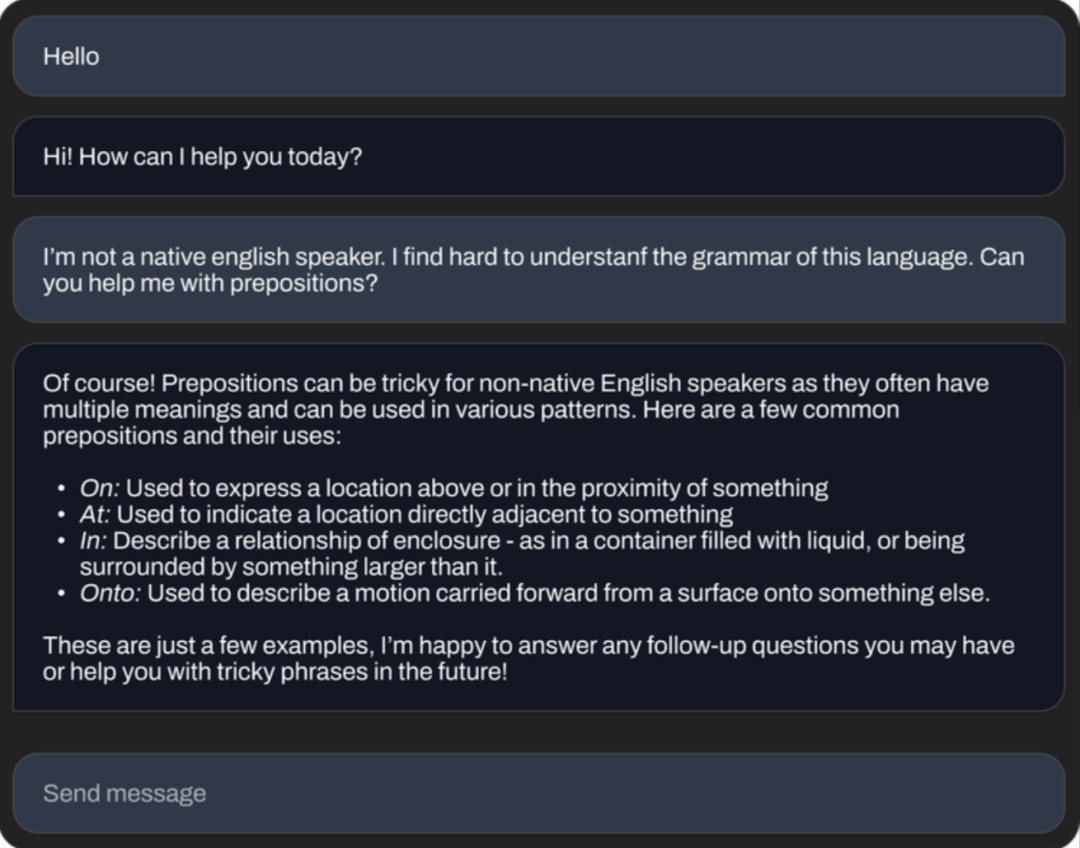
开源聊天机器人平替狂潮
Stability AI想做这样一个开源的聊天机器人,当然也是受了此前LLaMa权重泄露引爆的ChatGPT平替狂潮的影响。
从去年春天Character.ai的聊天机器人,到后来的ChatGPT和Bard, 都引发了大家对开源平替的强烈兴趣。
这些聊天模型的成功,基本都归功于这两种训练范式:指令微调和人类反馈强化学习 (RLHF)。

这期间,开发者一直在努力构建开源框架帮助训练这些模型,比如trlX、trl、DeepSpeed Chat和ColossalAI等,然而,却并没有一个开源模型,能够同时应用指令微调和RLHF。
大多数模型都是在没有RLHF的情况下进行指令微调的,因为这个过程十分复杂。
最近,Open Assistant、Anthropic 和 Stanford都开始向公众提供RLHF数据集。
Stability AI把这些数据集与trlX提供的RLHF相结合,就得到了史上第一个大规模指令微调和RLHF模型——StableVicuna。
训练过程
为了实现StableVicuna的强大性能,研究者利用Vicuna作为基础模型,并遵循了一种典型的三级RLHF管线。
Vicuna在130亿参数LLaMA模型的基础上,使用Alpaca进行调整后得到的。

他们混合了三个数据集,训练出具有监督微调 (SFT) 的Vicuna基础模型:
OpenAssistant Conversations Dataset (OASST1),一个人工生成的、人工注释的助理式对话语料库,包含 161,443条消息,分布在66,497个对话树中,使用35种不同的语言;
GPT4 All Prompt Generations,由 GPT-3.5 Turbo 生成的 437,605 个提示和响应的数据集;
Alpaca,这是由OpenAI的text-davinci-003引擎生成,包含52,000条指令和演示的数据集。
研究者使用trlx,训练了一个奖励模型。在以下这些RLHF偏好数据集上,研究者得到了SFT模型,这是奖励模型的基础。
OpenAssistant Conversations Dataset (OASST1),包含7213个偏好样本;
Anthropic HH-RLHF,一个关于AI助手有用性和无害性的偏好数据集,包含160,800个人类标签;
斯坦福人类偏好 (SHP),这是一个数据集,包含348,718个人类对各种不同回答的集体偏好,包括18个从烹饪到哲学的不同学科领域。
最后,研究者使用了trlX,进行近端策略优化 (Proximal Policy Optimization, PPO) 强化学习,对SFT模型进行了RLHF训练,然后,StableVicuna就诞生了!

据Stability AI称,会进一步开发StableVicuna,并且会很快在Discord上推出。
另外,Stability AI还计划给StableVicuna一个聊天界面,目前正在开发中。
相关演示已经可以在HuggingFace上查看了,开发者也可以在Hugging Face上下载模型的权重,作为原始LLaMA模型的增量。
但如果想使用StableVicuna,还需要获得原始LLaMA模型的访问权限。
获得权重增量和 LLaMA 权重后,使用GitHub存储库中提供的脚本将它们组合起来,就能得到StableVicuna-13B了。不过,也是不允许商用的。
DeepFloyd IF
在同一时间,Stability AI还放出了一个大动作。
你敢信,AI一直无法正确生成文字这个老大难问题,竟然被解决了?(基本上)
没错,下面这张「完美」的招牌,就是由StabilityAI全新推出的开源图像生成模型——DeepFloyd IF制作的。

除此之外,DeepFloyd IF还能够生成正确的空间关系。

模型刚一发布,网友们已经玩疯了:

prompt: Robot holding a neon sign that says "I can spell".



不过,对于prompt中没有明确说明的文字,DeepFloyd IF大概率还是会出错。

prompt:A neon sign of an American motel at night with the sign javilop

官方演示



下图可左右滑动查看更多



顺便一提,在硬件的需求上,如果想要实现模型所能支持的最大1,024 x 1,024像素输出,建议使用24GB的显存;如果只要256 x 256像素,16GB的显存即可。
是的,RTX 3060 16G就能跑。

代码实现:https://gist.github.com/Stella2211/ab17625d63aa03e38d82ddc8c1aae151
开源版谷歌Imagen
2022年5月,谷歌高调发布了自家的图像生成模型Imagen。
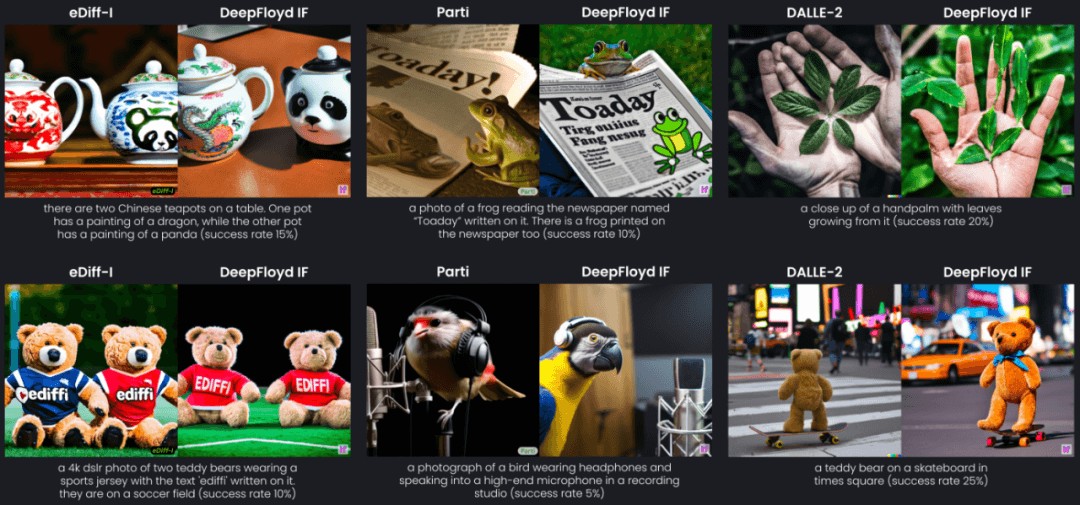
根据官方演示的效果,Imagen不仅在质量上完胜OpenAI最强的DALL-E 2,更重要的是——它能够正确地生成文本。
迄今为止,没有任何一个开源模型能够稳定地实现这一功能。
与其他生成式AI模型一样,Imagen也依赖于一个冻结的文本编码器:先将文本提示转换为嵌入,然后由扩散模型解码成图像。但不同的是,Imagen并没有使用多模态训练的CLIP,而是使用了大型T5-XXL语言模型。
这次,StabilityAI推出的DeepFloyd IF复刻的正是这一架构。
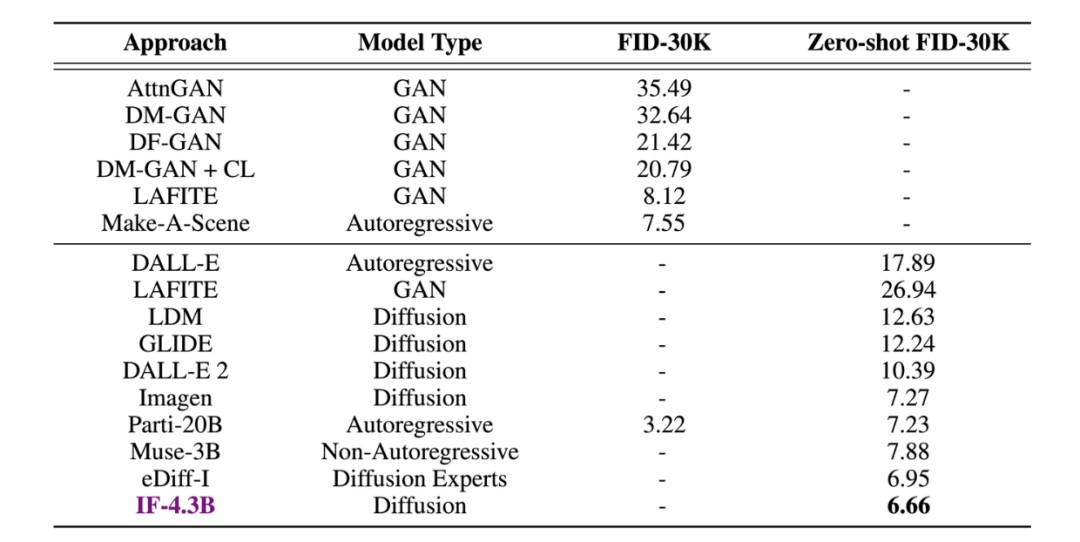
甚至在测试中,DeepFloyd IF凭借着COCO数据集上6.66的zero-shot FID分数,直接超越了谷歌的Imagen,以及一众竞品(包括自家Stable Diffusion)。
下一代图像生成AI模型
具体来说,DeepFloyd IF是一个模块化、级联的像素扩散模型。
模块化:
DeepFloyd IF由几个神经模块组成(可以解决独立任务的神经网络),它们在一个架构中相互协同工作。
级联:
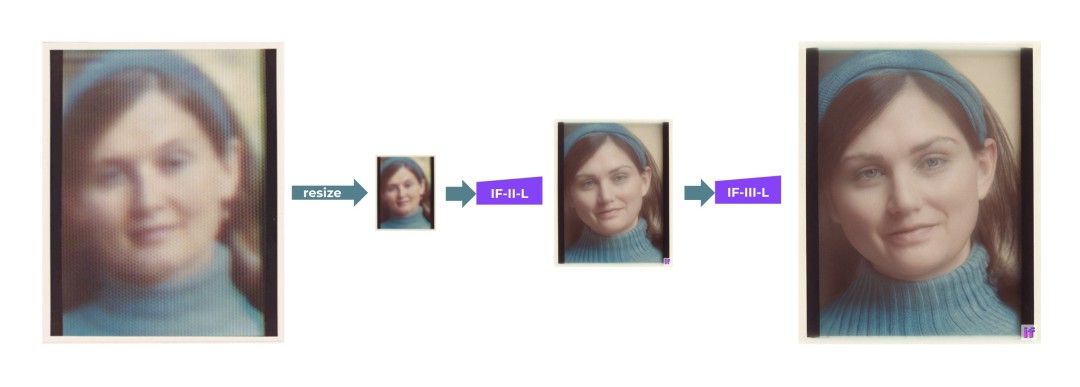
DeepFloyd IF以多个模型级联的方式实现高分辨率输出:首先生成一个低分辨率的样本,然后通过连续的超分辨率模型进行上采样,最终得到高分辨率图像。
扩散:
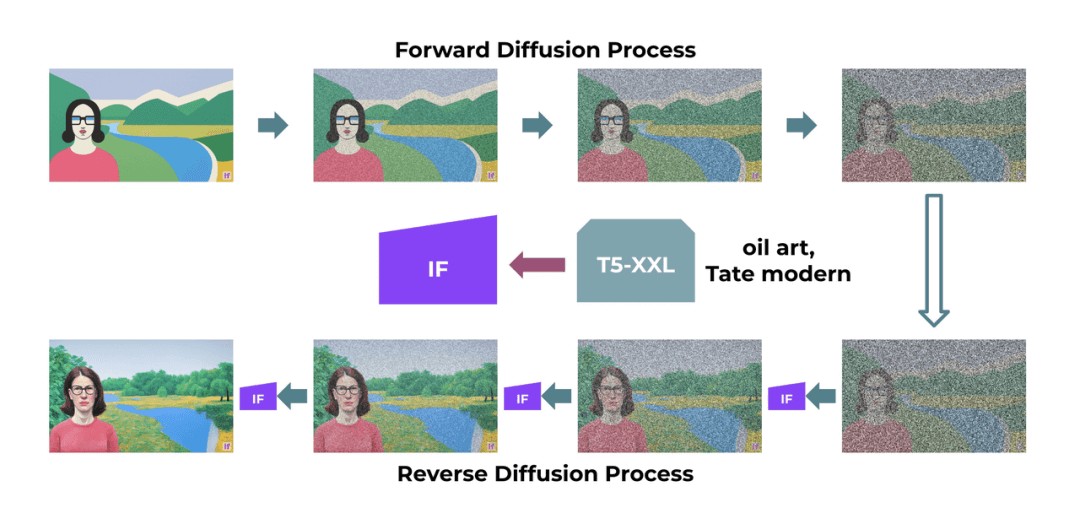
DeepFloyd IF的基本模型和超分辨率模型都是扩散模型,其中使用马尔可夫链的步骤将随机噪声注入到数据中,然后反转该过程从噪声中生成新的数据样本。
像素:
DeepFloyd IF在像素空间工作。与潜在扩散模型(如Stable Diffusion)不同,扩散是在像素级别实现的,其中使用潜在表征。
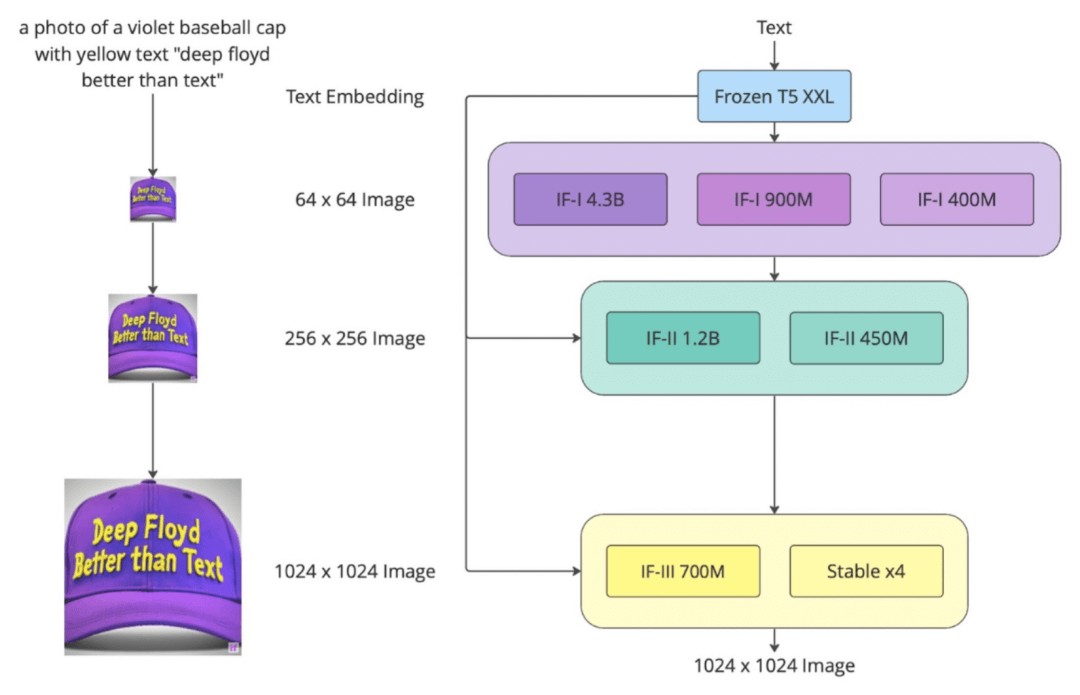
上面这个流程图展示的就是,DeepFloyd IF三个阶段的性能:
阶段1:
基本扩散模型将定性文本转换为64x64图像。DeepFloyd团队已经训练了三个版本的基本模型,每个版本都有不同的参数:IF-I 400M、IF-I 900M和IF-I 4.3B。
阶段2:
为了「放大」图像,团队将两个文本条件超分辨率模型(Efficient U-Net)应用于基本模型的输出。其中之一将64x64图像放大到256x256图像。同样,这个模型也有几个版本:IF-II 400M和IF-II 1.2B。
阶段3:
应用第二个超分辨率扩散模型,生成生动的1024x1024图像。最后的第三阶段模型IF-III拥有700M参数。
值得注意的是,团队还没有正式发布第三阶段的模型,但DeepFloyd IF的模块化特性让我们可以使用其他上采样模型——如Stable Diffusion x4 Upscaler。
团队表示,这项工作展示了更大的UNet架构在级联扩散模型的第一阶段的潜力,从而为文本到图像合成展示了充满希望的未来。

数据集训练
DeepFloyd IF是在一个定制的高质量LAION-A数据集上进行训练的,该数据集包含10亿(图像,文本)对。
LAION-A是LAION-5B数据集英文部分的一个子集,基于相似度哈希去重后获得,对原始数据集进行了额外的清理和修改。DeepFloyd的定制过滤器用于删除水印、NSFW和其他不适当的内容。
目前,DeepFloyd IF模型的许可仅限于非商业目的的研究,在完成反馈的收集之后,DeepFloyd和StabilityAI团队将发布一个完全免费的商业版本。
参考资料:
https://stability.ai/blog/stablevicuna-open-source-rlhf-chatbot
https://stability.ai/blog/deepfloyd-if-text-to-image-model
本文为专栏作者授权创业邦发表,版权归原作者所有。文章系作者个人观点,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。







