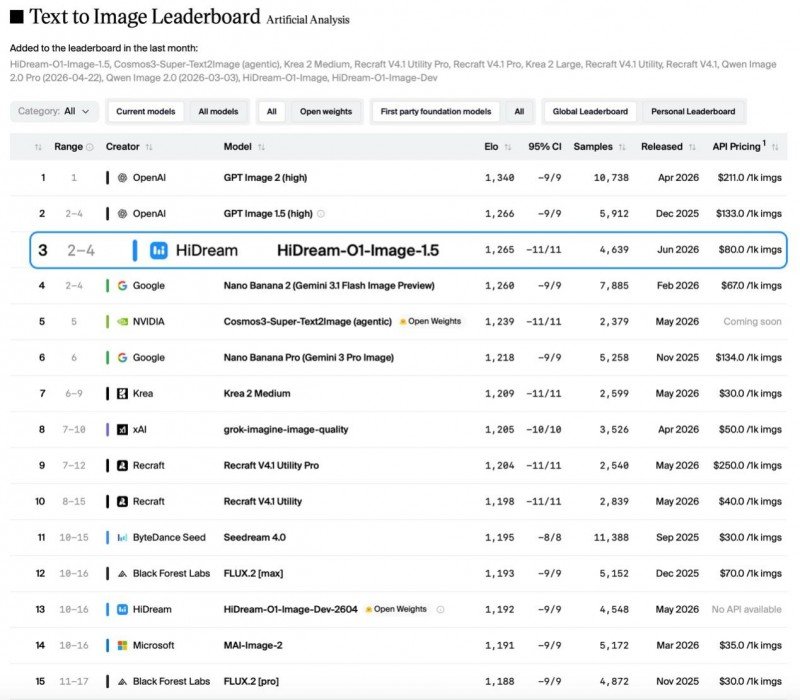
在生成式人工智能的竞赛中,图像生成赛道正迎来新的挑战者。近日,智象未来(HiDream.ai)凭借其商用图像生成模型 HiDream-O1-Image-1.5,在国外文生图榜单上斩获 1265 ELO评分,位列中国第一、全球第二,仅次于OpenAI。这一成绩不仅超越了 Google Nano Banana 2(Gemini 3.1 Flash Image Preview)、NVIDIA(Cosmos3-Super-Text2Image)和字节跳动(Seedream 4.0)等巨头的模型,也让外界再次将目光投向中国团队在视觉生成领域的底层架构创新。
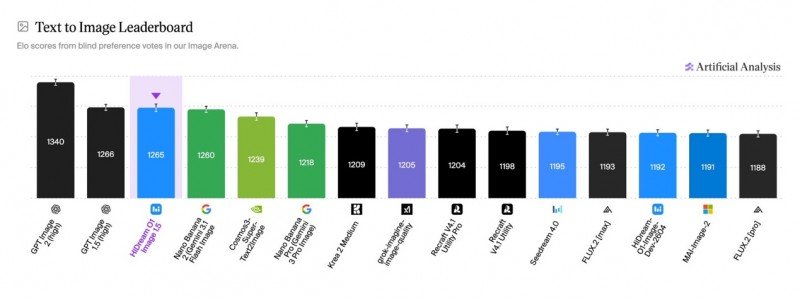
从开源登顶到商用霸榜,仅隔半月
就在半个月前,智象未来开源的 HiDream-O1-Image-Dev-2604 刚刚登上同一榜单的开源模型全球第一。如今,商用版 1.5 又快速跻身全榜前三,形成“开源+商用”双线领跑的局面。
“原生全模态”架构:告别模块化拼凑
HiDream-O1-Image-1.5 的技术核心,是其 原生全模态架构 Unified Transformer(UiT) 。与传统文生图模型常见的“文本编码器+VAE+扩散模型”模块化路径不同,UiT 从底层将图像像素、文本 Token、视频体素以及音频、动作、空间关系等原始信号映射进同一个共享 Token 空间,由同一套 Transformer 完成理解、生成和推理。这意味着模型不再需要在不同模态之间反复转换信息,从而在文字密集排版、多主体生成、分镜叙事等复杂任务中显著减少了细节损耗和语义错位。
智象未来也是业内首家将这一架构从“技术验证”推进到 “生产验证” 的公司。开源版证明了路线的可行性,商用版 1.5 则在广告营销、电商视觉、影视分镜、IP 创作等真实商业场景中展现出强交付能力。
不只是“画得好看”:会写字、懂排版、能分镜
评测数据显示,HiDream-O1-Image-1.5 并非只在单一维度上表现突出,而是在多个应用场景中同时具备竞争力:
人像与动物摄影:在皮肤质感、皮毛细节、复杂光影和水下折射等场景中保持摄影级真实度,肢体比例和空间透视稳定。


电商海报:能够将商品、场景、装饰元素与中英文营销文案自然融合,即使在多层级卖点和复杂排版下,文字可读性和画面完整度依然出色。

IP形象设计:围绕同一角色生成多角度视图和多种情绪表情,保持五官、发型、服饰的高度一致性,可显著提升角色三视图开发效率。

多宫格/分镜设计:可生成逻辑连贯的连续画面,并自动维护角色、场景与视觉风格的统一,支持影视分镜、漫画创作和广告脚本的快速视觉化。

多层次文字渲染:在中英文混排、数字公式、图表信息和多级标题等复杂需求中,仍能保持较好的可读性与版面稳定性,拓展了教育培训、办公协作等场景的实用价值。

对比谷歌Nano Banana 2:复杂中文与光影细节胜出
日前,有博主发布了一组图片,将HiDream-O1-Image-1.5 与 Google 的 Nano Banana 2(Gemini 3.1 Flash Image Preview)进行了直接对比。其中一个 Prompt 要求生成“中国白酒奢华电商海报”,需要在羊脂玉瓷瓶表面浮雕一首八句中文古诗,文字内部镶嵌金箔,并配合黑板岩、浅水池、焦散光影和盆景松树等复杂元素。结果显示,HiDream-O1-Image-1.5 在中文文字的准确渲染、金箔材质的金属光泽、以及水面焦散光效上都明显优于对手。另一组“好奇小猫探索童话花园”的提示中,其花朵的层次感、光影的柔和过渡也获得用户更高偏好。





从图像生成到“世界模型”的入口
智象未来的长期目标是构建原生全模态世界模型。其认为,一张图像承载着现实世界某一时刻的主体、空间、材质、光影和关系——只有稳定理解并生成这些状态,模型才能进一步处理连续时间中的运动、因果、镜头和叙事。HiDream-O1-Image-1.5 的表现证明了 UiT 架构的可扩展性,也为后续多图一致性、视频首帧生成乃至长视频生成提供了更稳定的底层能力。
目前,HiDream-O1-Image-1.5 已在官方平台 vivago.ai 和 hiharness.ai 开放体验。开源版本也已在 GitHub 和 Hugging Face 上线,供开发者下载使用。
从依赖“更大参数”和“更美画面”的旧竞争,到由架构能力、生产效率和工作流价值共同决定的新阶段,HiDream-O1-Image-1.5 的登顶不仅是中国大模型企业在全球顶级赛道上的一次亮剑,也印证了原生全模态路线作为下一代多模态模型底座的可行性。对于内容创作、商业营销、影视制作等产业而言,一个能够“理解图文、掌控排版、叙事分镜”的 AI 生成工具,或许正在重新定义视觉生产力的边界。







