编辑丨沃特敦
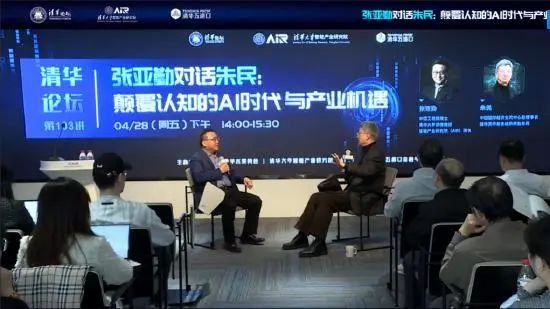
4月28日,清华论坛迎来了本校的两位大神级人物。一位是科学家张亚勤,12岁就读中科大少年班,之后担任微软亚洲研究院院长和百度总裁,目前是清华智能产业研究院院长。另一位是经济学家朱民,曾任IMF副总裁、中国人民银行副行长,现在是清华国家金融研究院院长。两颗最聪明的大脑围绕当前最火爆的话题ChatGPT展开了长达100分钟的对话。
创业邦经授权刊发此次主题对话《颠覆认知的AI时代与产业机遇》,内容经编辑整理。
朱民:我们先谈谈你的智能产业研究院。三年了,你现在做的怎么样,主要在做什么?
张亚勤:2019年底我离开百度,一直想做一个研究院,和当年20多年前微软亚洲研究院在某些方面相似,都是从事基础研究。但这个研究要为产业服务,解决真正的问题。另外,微软研究院是企业做的,我希望研究是面向整个产业开放的。还有一点在于清华,有最优秀的学生和老师。所以,研究院的缩写AIR的意思也很简单,就是AI for industry research。这里I的话有三个含义,就一个是国际化(international),一个是AI,一个是产业(industry)。
现在我们有21位全职老师,还有博士生、博士后研究人员,还有学生一共200多人。目前研究院的主要研究还是人工智能。由于我们面向产业,所以选择了我们认为有很大机遇的三个方向:机器人和自动驾驶、生命和生物科学,另外是物联网,特别是面向双碳的领域,我们叫绿色计算。
朱民:最新的突破在哪里?
张亚勤:我们一直从事这些算法,包括模型方面的研究,我们和很多企业合作,在语言模型,比如多模态、强化学习、联邦学习,然后也做一些垂直模型,比如说面向自动驾驶机器人的,面向生命科学的。前几天还开源了一个生物医疗的GPT,叫BioMap。在自动驾驶方面,我们也有一个基础决策感知的模型。
朱民:所以你的研究也是和现在崛起的ChatGPT和GPT大模型的趋势是一致的。我们就聊聊大模型,这是现在最热的事儿。ChatGPT当然是惊艳,一出来以后又能画画,作诗、写歌。可能大家听说了它做了一个贝多芬的音乐。
当然,作为一个老贝多芬的爱好者,我觉得它做的不怎么样,但它居然也是能装模装样做作曲了,还有4个乐章,太搞笑了,但它确实影响很大,写代码做文件检索都做的很好。关于它的争论很多,有观点认为它已经走向AGI,也有观点认为它还不成熟,技术上并没有很大突破,只是商业模式用的好,路径好,它很聪明。你是真的专家,你怎么看这件事?
张亚勤:你刚才讲的是过去这2-3年,一个大的趋势就是生成式AI。ChatGPT可能做的最成功,其它的也包括比如像DALL-E、stable diffusion,等等一系列的生成式AI。
ChatGPT推出之后对我的震撼还是挺大的。前段时间谈到“我的GPT时刻”是什么样的?我有三个想法,第一个我感到就是人类历史上第一次我们有了一个智能体,然后通过了图灵测试。
朱民:通过了图灵测试,我们回头再说这一点,这个是个了不得的结论。
张亚勤:对,图灵测试,咱们知道是图灵1950年提出的,机器可以thinking,是可以思考的机器,然后提出了图灵测试。它是我们做计算机科学这么多年梦想的一个目标。ChatGPT我认为是第一个软件智能体通过了图灵测试。我太太是ChatGPT或者GPT这些产品系列的大粉丝,当时我在看的时候,她说ChatGPT也能幻想,也经常说错话,也会说谎,我说那和人类就更像了。
所以,第一点还是通过了统一测试,包括语言对话的引擎(conversational AI),其实对话引擎也很多年历史了。1966年MIT第一个做出了对话的引擎ELIZA,这么多年有很多次迭代,到了Siri,到了Alex,到了Cortana,然后国内有小度,有天猫精灵,有很多对话的产品,都是针对某一些领域或者聊聊天,或者某些领域。
朱民:包括微软的小冰。
张亚勤:是的。包括小冰,都是对话引擎的产品。但ChatGPT在功能和通用性方面远远超过了早期的产品,它用了大规模Generative AI,这是我第一个感受。第二个感受,我认为它是AI时代的一个新的操作系统,就像在PC时代Windows,移动时代的iOS。一会我们可以再展开讲。
朱民:我觉得这个比你的第一个结论更重要,因为过了图灵测试,这是过去。如果是新操作系统的话,那是一个巨大的未来。
张亚勤:就会重写、重塑、重建整个生态系统。第三点咱们原来也讨论过,我认为它是我们从面向具体任务的AI走向通用AI的一个起点。虽然ChatGPT更多的是大语言模型,大基础模型,但它开启了一个亮光。因为我们多少年也是在往那个方向走。这就是“我的ChatGPT时刻”。
我经常跟我们的学生老师讲,这么多年来AI,还有整个IT领域,出现了有好多热词,一会儿是区块链、加密货币、比特币;一会儿又是Web3.0、NFT、元宇宙。有些可能是真的,有些可能是个概念,但整个大语言模型,包括ChatGPT,GPT4.0,这是一个大的变革。
朱民:所以这次是真的让你兴奋了,让一个科学家兴奋就表明something is happening。所以这个还是挺有意思,图灵测试过了,因为机器和人对话,当然还有很多误差,它会撒谎等等,因为它是token system,这个都是在不断完善,并且通过人类的反馈机制训练,我觉得Fine-tuning都会不断提高,这个没问题。
张亚勤:你们听朱民讲,他在讲算法,他完全不像是央行的副行长。
朱民:这个是跟你学的。但是你大操作平台可有意思了,因为现在ChatGPT出现了API,然后出现了插件,所以它逐渐可以把专业的东西放进去,垂直系统,然后现在出现了plugins,plugins出来又是一个特殊的路,很多东西又可以往上放。所以,如果以后变成生态的话,真的是一个大的操作平台,然后就会出现一个我们以前讨论过的super app,整个的产业就被彻底颠覆了。这个在什么情景下会发生呢?
张亚勤:尽管目前有新的插件也好,API也好,或者新的应用也好,本质其实并没有变化。大家都记得在PC上面本身也有很多应用,Office就是一个大的超级应用,到移动时代的话,有的操作系统上面有应用商店,上面也有很多超级应用,微信、短视频、淘宝、搜索等等,都是上面的超级应用。
我觉得AI时代也会很像,有一个大模型作为操作系统,plugin也好,API也,在上面你就可以有APP。有很多APP可能需要有垂直的模型,因为有些行业比较深,比如自动驾驶、生物计算等等,但这些垂直模型可以建立在横向的大语言上,这个大语言不仅仅是语言,其实是多模态的,也包括视频、图像,语音等等。有了这个之后,你的垂直模型也好,包括你刚才讲的,它都有更多的应用。
你刚才提到一点很重要,现在大语言模型,或者说我们的基础模型,它自己是个工具,它也可以使用别的工具,它可以去使用比如说Hugging Face各种开源的这些数据、模型,然后去执行新的任务或者构建新的应用。同样,我们也可以用不同的大模型,然后去构建新的应用。也就是说,大模型可以使用你,你也可以使用大模型,彼此互相使用。
朱民:以后想象中的世界,因为智能了,机器就自己讲话了,它已经脱离人了。一旦你给了数据,机器自己生成,生成完又出现智能,然后它就可以自己交流,自行不断地改进,那是不是一种新的物种正在出现?
张亚勤:可以这么理解。
朱民:这又是一个很重要的概念,我们理解的物种都是电影里的外星人。如果把AI大模型看成一个物种的话,那就是大家讨论的关于人类面临的根本挑战了。是这样吗?
张亚勤:首先是一种新的能力吧,叫物种也好,能力也好,比如说现在GPT4plus,之后还有4.5、4.9、5.0。5.0主要的开发者是谁呢?是4.0,所以它自我在开发,自我在迭代,自我在进化,所以这是一种和人类一样的、很强的能力。
但我并不认为人类会被替代,我觉得AI还是一个工具,是我们的延伸。也就是说,我们人类、我们碳基生命有这样的一个智慧,我们可以发明东西,我们也可以去控制它,让它按照我们的方向去演化。我是乐观者。
朱民:对,你是乐观者,我也是乐观者,但最怕的是过分乐观,我们要小心。这其实是很有意思的一件事,我们先不讲人类和机器的对比,现有的人其实提出了哲学命题,或者提出了一个根本的问题,就是AI是人的智能的一部分,还是人的智能之外的,一种新的或者人还没有悟到的智能。你怎么看?
张亚勤:这是一个特别好的问题。我认为现在的大语言模型,它的很多智能是我们不知道的。我们可能有,但我们没有认识到的,因为我们所认识到的知识,我们所看到的所谓的智能,其实是我们人类很少一部分。然后,机器把一部分我们有的但不知道的,找出来了。但它可能会有新的能力,但我不希望大家有一种想法,就是新能力会像科幻电影里说的那样把人替代了。未来的智能一定是Human Intelligence,一定是人类的智能和机器智能的一个融合,而且机器一定是我们的一个很强的延伸,它很多事做了我们可能做不了。就像汽车一样的,汽车跑得比人快,它比人有更强的能力,但它并没有替代人。
朱民:工业革命是扩展了人的肌肉,现在是AI要扩展人的智能,我觉得这是一个很大的判断。现在关于机器智能究竟是人的智能的发现,还是一种人的潜在不知道的智能的挖掘出现,或者是更新的一个我们根本就不知道的智能,所以你认为是?
张亚勤:我觉得三者都有。
朱民:这个很有意思,所以从这意义上来说,根本的一个fundamental的哲学问题是,智能不只是人类独有的。
张亚勤:是的,就看你怎么定义。比如生存的能力、繁殖的能力。繁殖能力很强的物种,最强的不是人,是细菌,是病毒,你像新冠那么小的一个病毒,可以给我们造成这么大的麻烦,对吧。而且它上几十亿年就存在,它的寿命也一定会比我们人类要长,所以我觉得我们智能有很多不同的维度,不同的方面。发展到现在,给我们提供了很多新的启示,包括就是延伸我们。
我再讲一下,就是说我们可能还是要把智能分成几个不同的层次,然后有些东西我们要有边界。
这个又回到图灵了,还是机器第一个层次是感知,就是我要听得见,要能说话。就是视觉、语音识别、语音合成、人脸识别,图像识别,包括文字OCR都属于这种感知层面的方面。现在机器已经比人厉害了,机器识别人脸比人可能厉害,我觉得这个可能5年前基本上就和人是同样一个水平了。
第二层次智能的话是可以思考,可以决策,可以推理,在这个认知层面,现在的大语言模型出来之后,和人的距离就差距就越来越小。过几年,在这个方面,就和人类差不多了。现在大家看到说ChatGPT考试比人还厉害,能考SAT。两个星期前,我的一个朋友在北大教量子力学,量子学是很难的,她期中考试已经高于班里的50%,它也没有经过任何专门的学习。所以说机器在认知方面也会和人类差不多。
另外还有几个层次,我觉得是我们不应该去触碰的。我一直在讲,我们做AI伦理也好,治理也好,比如说它的个体能不能作为独立个体?人工智能有没有自我意识?它有没有感情?这些方面我不认为我们可以达到,但我也不认为我们人类应该做这样的研究,就像基因编辑某些方面我们不应该去触碰。
另外就是人工智能的治理。人工智能需要一个边界。咱们有信息社会、有物理世界、有生物世界。在这些世界,其实这些空间都在走向一种融合,新的数字化走向融合,但我们需要有一些边界。比如ChatGPT可能先把它放到信息世界里面,然后如果真正去到了物理世界。自动驾驶我们可能要小心点,还有金融系统。
我刚在新加坡开会,在两个不同的场合。一个是WPP公司,做广告策划的。如果是做创意,我就鼓励多用ChatGPT这样的东西。但在银行,我觉得你先别用,你可以用作为信息类的,但牵涉到核心金融系统,涉及交易的,还是要比较小心。
朱民:所以,科学家既有乐观也有谨慎。从乐观的方面,毫无疑问这是个颠覆,但从谨慎的方面,我们还是要很小心地划个边界。在我们不知道的情况下,我们先谨慎,我觉得这个还是很有意思的。但这个边界是会被不断地突破的。你刚才讲了一个特别重要的概念,就是工程应用。人工智能现在越来越多地被认为是工程学,你可以应用大模型,大模型也可以应用你的这个东西,所以它越来越变成一个工程了。如果从工程学角度看大模型,大模型的发展会怎么样?
张亚勤:我觉得它肯定是会变得越来越准确,然后变得越来越成熟,而且它进化的速度也会越来越快。但是,在我们没有很清楚它的成熟度之前,我们需要给它个划边界。
我相信对我们以后整个物理世界,比如说机器人自动驾驶,对于物联网都会有很大的应用,但我觉得根据你的需要不一样,应用不一样,就更要谨慎一些。比如对于核心的任务(mission critical),我们还是要有更多的可控性,因为现在生成式AI,它生成什么东西我们并不完全知道。而且,不仅我们知道,我们甚至不知道为什么会发生这样的事。我们只知道一部分。
朱民:所以这又涉及到我们现在大模型的根本概念,emergence「涌现」,这个是以前没有的。因为它开始有数据逻辑推演以后,它开始「涌现」一些非线性的发展。这个「涌现」怎么讲?它未来的发展前景怎么样?我觉得这是一个很重要的问题。
张亚勤:朱民行长讲了一个特别重要的概念,这个都是比较专业的词汇,叫做「涌现」emergence。
emergence确实目前是在这种大模型里面,当模型的参数体量大到一定程度的时候,基本上是到了百亿参数的时候,开始「涌现」,就是你可以看到它在准确度还是可预测性都跳跃式提高。为什么这个时候出现「涌现」,具体这些数学模型或者因果关系,现在并不是很清楚。
但你可以这样想,当我的数据量体量大到一定程度的时候,参数到一定程度的时候,而且我的训练方法是正确的。这个很重要,数据是高质量数据,我训练的方式是正确的,可以利用这么多数据,有好的方法时候。
如果用一个拟人化的来比喻,我们每天读书,读到一定的时候忽然就开窍了。灵光一闪,开始的时候,读书只是填补个知识,但到了一定程度我就可以掌握这个规律了。比如我建的大模型,参与到一定程度之后,它把真正的架构(Structure)找出来。
朱民:这里又提出一个重大哲学问题。如果「涌现」是像灵光一闪那样的跳跃式的变化。我们人的经历都讲有顿悟,但顿悟是有点智慧含义的,「涌现」是智慧吗?
张亚勤:你可以这样理解。如果拟人的话,就是参数到一定程度之后,它忽然就很准确了,就像语音识别,贯通了。这个非常重要。如果你直接看的话,由于我数据量特别大,参数很多,因为它做预训练的时候用的是这个叫自监督学习,然后它自己是In-context learning,在它这个语料很大的时候,它要把里面一些mask出去,然后自己去训练自己,所以模型大到一定程度时候,它准确率就比较高。
但是为什么会在那么多参数的时候会这样,而且不仅仅ChatGPT,很多别的大的模型,不仅是openAI的,很多别的模型也有类似的这么一些现象了。
所以这个现象我不能讲是这个灵光一闪,是哲学或者宗教的概念,但是我们现在并不清楚为什么,清楚一部分,但不清楚全部。所以这个是emergence.
然后包括另外一个是统一性,这也是现在GPT里面T很重要一部分。过去可能对不同的任务有不同的算法,现在有了transformer之后,不管你是语言也好,还是语音也好,还是图像或者是视频或者是蛋白质,你都可以用token based里的token转化。这跟人的大脑思维方式比较像,我们的neural,都是neural。
朱民:所以我们现在又往里走一步,现在如果回到深层的方法上面来看的话,两三年前都有一种议论,说深度学习已经不行了,是吗?
张亚勤:我没有听到。
朱民:大概四五年以前开始,有很多这样的说法,就是觉得深度学习,大数据的应用开始出现了小数据。那么现在的新的工具transformer是一个foundation。这个是一个很重要的基本结构。GCAI或者AIGC是一个很重要的方向approach,那么技术上来说,你觉得transformer模式成型了?还是以后会有怎么样的发展?因为你是科学家,咱们得想一想科学的问题。
张亚勤:第一个我认为transformer确实是挺了不起的,当时2017年Vaswani在Google,当时一开始是为了其实在做Google translate来做的这么一个算法。这个算法出现之后,确实是把整个深度学习的进展推到更高的一个层次。但是,如果我们看一下transformer或者看一下包括现在大模型,其实它的效率还是比较低的。
我们再和大脑比一下,我们人的大脑经过几十万年的进化,确实不得了,差不多不到三斤的大脑,然后有860多亿个神经元,每个神经元差不多有1万个Synapse突触,你如果把每个连接做一个相当于参数的话,我们大脑比现在GPT4,我假定是1万亿,比它要高上千倍。我们就三斤重,而且我们功耗30瓦,你这GPT功耗多少瓦,所以我觉得我们效率还是很高的。而且目前这种大模型,虽然让很多工作变得更高效,但耗电和运算的效率还是很差的。transformer当然是很好的一种算法,但在计算方面确实十分耗能。
朱民:所以从能耗来说还会有很大的突破的空间。
张亚勤:我认为5年之后也许就会有一个不同的算法。
朱民:怎么叫不同的算法?
张亚勤:就也许就不是transformer算法,也许是,也许不是。
朱民:你会发明一个吗?
张亚勤:我把希望寄托在我们的博士生上。
朱民:回到工程学,工程学就很有意思了,因为它等于一个辅助工具,它无所不能了。所以我觉得现在比较有意思的一点,用我的语言来说,是大模型的脱虚向实。所谓虚就它离开了服务业,实,就是说它进入了物理世界,去操纵和管理物理世界。我觉得这是一个工程学的很重要的概念和一个很重要的应用场景。
所以现在我们出现了AI for science,而且现在科学研究进入了第四范式。那么就把整个科学研究的方法全部变掉了,是数据主导,不再是独立的由根开始往上走,而是逆向发展,这个就很厉害了。最近的很多事,比如说常温超导,这个卤是算出来的,最近的可控核聚变,可控是大模型控的。蛋白质,现在我们已经有了那么多三维的蛋白质的结构分析,你也做生命是吧?大模型在科学研究方式的方面,对它将来会怎么样?
张亚勤:这是特别好的问题,我稍微花半分钟讲一下范式这个定义,其实提出第四范式,包括最近提到的第五范式,都是微软的科学家提出来的。范式从最早在亚里士多德,后面到了伽利略。牛顿是第一次把所谓的第一范式数学化方程式化,包括到Maxwell,包括薛定谔,爱因斯坦后面是方程式的第二范式。第三范式是计算机出来之后的事。后面大数据来了之后是图灵奖获得者Jim Green提出的数据驱动,就是第四范式。
最近微软英国的科学家又提出第五范式,就是深度学习。作为科研的一个新范式,我认为第四和第五基本上是不同阶段,你可以都叫第四范式。
这里面有很多新的工具,比如刚才你讲的工程学,新的工具可以使用,就是我们可以把我们方程式的东西,结合到我们观察的,测量的数据里面来。比如我们现在可以生成大数据,用方程式来生成,加上我们观测的数据把它结合起来,开始预训练,然后结合起来。
朱民:是。现在的科学研究上或者说是第四范式也好,出现了两种流的合作,一个是人的流,他把一些观察到想象中的参数什么放进去,一个是数据位自由,就机器深度学习,然后让这两种东西结合起来,是朝我们想象中的用预训练的模式来实现它的未来,所以这个很有意思。人工智能和人的智能开始合作,那么现在看的比较多的是材料科学,数字材料现在是很明显,生物对蛋白,做three dimensional structure这个也是很多的。你觉得像物理或者数学这种根本的科学研究,在方法论上会被颠覆吗?我觉得化学是很容易突破的。
张亚勤:我认为会的,但是怎么颠覆我也不是很清楚。我那天开玩笑说我现在比较保守了。我说5年意义,我们所有的奥林匹克的冠军,数学、物理包括所有的考试,冠军一定是机器,从阿尔法狗开始,一定是机器。另外,我认为AI可以证明一些我们没有证明的事儿,哥德巴赫猜想等。
朱民:我觉得科学家还是很严谨的,哲学家可以在这个天空里思索。
张亚勤:新的方程式以后可能是AI发明的,这都有可能。
朱民:量子力学就会可能会有很大的突破,所以这是一个很大的事情。如果科学有这么大这么变化的话,反过来人类的进化速度会大大加强。5年真的是一个很短的时间。
张亚勤:刚才你问的特别好,就是科学的范式。其实如果看一下我们物理学,每一个科学都需要一种描述的语言。数学是物理学最好的描述的语言。我认为AI整个来讲,从我们这种发展的方向,不一定是GPT,也会成为一个好的描述的语言。当科学的东西没法去表示出来的时候,我就用一个大的模型加上一个参数去表示它,然后它就变成一种新的语言。
朱民:讲到现在我们已经走得很远了,天马行空。那么落地到现在的话,大家很关心中国的大模型发展怎么样?现在百度出了文心一言,现在我看能列出的大模型大概有几十种了。
张亚勤:百模大战。
朱民:当然困难是很明显的,第一个是,美国把芯片卡住了。那么算法当然也受到很大的影响;数据也有一个质量和规模的问题;对语言也是个问题,对中文和英文之间其实还是在自然语言处理的方面还是有不一样的。你怎么看百模大战中国的差距究竟有多大?我们怎么干?
张亚勤:不想得罪人。(现场笑声)
朱民:科学家没问题的。我先说我的观点,我不怕得罪人(现场笑声)。我1月7号的时候我说,大模型,中国落后两年。
张亚勤:对,我觉得大模型方面肯定是落后的,具体落后多少我就不说了。但是,目前这么多企业,包括BAT、华为、字节在内的很多大公司都在做大语言模型,包括新创公司,大家都在做,最后就是充分竞争。只有经历充分竞争的企业才是好企业。而且中国的竞争有中国的特点,这些人都是经过互联网时代的千锤百炼,经历过血腥的竞争,知道怎么竞争。第二点就是在竞争的过程中,每个企业的人都很聪明,他自己会去定位,就让市场去检验它。政府就别管了,政府鼓励竞争就行。
我个人看的话,可能最后会有五六个大模型。所有的操作系统,大部分的话可能还是面向行业的很多垂直模型,它会结合大模型解决行业大的问题,但在每个行业可能也需要细分。
你刚才提到芯片和数据,我稍微讲一下。数据是问题也不是问题,就第一点你看目前大模型也没有人把充分把自己的数据都用了,以及比如企业外面我们有很多这种公用的数据,然后每个企业刚才我讲的大企业都有自己好多数据,他都没有用完,可能用了很少一部分,因为时间不够,这几个月。然后第二点就是你看现在做多模态,刚才讲的语言多模态里面多少视频的数据,多少这些图像的数据也都去使用。
还有一点。你看GPT用了很多中文的数据,用了很多法文的很多各种不懂语言的数据,咱们也可以用别的语言,我们完全可以用英文的数据,对吧。
这些数据能用就用,所以我认为长期不是大问题,短期也不是大问题。而且说实话,数据不仅量要大,重要的是你怎么样去清洗它,怎么样把它变成高质量的数据。其实做大语言模型也很有意思,就是数据太轻,太干净也不行,还是需要一些有免疫力的,就像人身上需要一点有要和细菌和病毒共存的时候需要一点免疫力,所以怎么样去获得这个数据,其实是做大语言模型,1/3的工作是关于怎么样把这些数据叫data engineering很重要。
算力的确是比较挑战,如果咱们把中国所有的算力加在一块,现在至少也有50万个,至少50万个A100这么一个体量加在一块,你训练100个模型有点小问题,但是训练5个模型是没问题的。另外一点,这个东西你也不是永远在用它,你在预训练的时候用它,用了之后你几个月可能就不需要用这个东西了。
还有一点,现在很多的工作是怎么样把这个模型简化,然后怎么样小型化边缘化。所以我认为这些东西是有挑战,但不能是我们两三年之后没做好的一个借口。我认为我们一定会做的不错的。
然后还有一点就是中国自己也在做芯片,现在你看到有昆仑,汽车的地平线等等许多公司都在做这些芯片。
朱民:所以你还是乐观的,算力算法和这个数据,我们还是有资源可以解决,是吧?但是大模型它有几个特点,第一个是它进入的门槛很高,它不是一个可以自由竞争的世界,是第二个它有些地方具有天然的垄断性,算是有垄断性的,算法取决于你是不是开源。而且这个规模也使得进去不那么容易。所以在这个情况下,那是一种市场充分竞争,还是一种类似于寡头竞争。未来的中国发展大模型的路径大概是个什么情况?
张亚勤:如果把大模型比喻成42公里的马拉松,现在跑了5公里,目前是春秋战国,大家要充分竞争。等竞争到一定程度,肯定就不可能有那么多大模型了。就像操作系统和云一样,一开始有多少朵云?现在的云,不管美国也好,中国也好,最后可能就四五朵云。所以我认为最后肯定是要收敛的。
朱民:你还是很乐观,中国人会长出自己的大脑模型。
张亚勤:对。但我想讲一点,我们现在不能假设就是那几个大公司的事儿,初创公司也有希望,OpenAI就是一个小公司。所以大家都有机会。但平台的门槛很高。比如我们这样的研究院,我们一开始就说不要自己去做大型语言模型,我们也不会去买上万个GPU,很多工程的东西我们也不会去做,我们可以和企业去合作。
朱民:这就提出了很重要的一点。在我们追赶的道路上,第一个是算力算法数据,你有没有底气?第二个是市场准入竞争公平,这个结果会怎么样?但形成生态合作共赢还是很重要的。你看大概会是怎么样的一个生态呢?
张亚勤:比如说N年多之后,4-5年之后会有几个大的模型,就是可能主要在云上面,在云上面有大量算力的,有这么横向的,我把它叫做AI的云的操作系统,在这个上面有很多的vertical很大的一些apps,而且我认为有些apps会在一个云上一些APP在很多云上,有些souper apps可能它会调用不同的models的,刚才你讲的工程化和工具化,你可以用你的操作系统可以用别的,别的APP,我也可以用我这个APP也可以用好多不同的模型,然后可以用open source模型,也可以用这些商业化的模型,还有一个open source,现在这是很重要一个力量,不在我们刚才讲的这些里面。
朱民:你看现在美国出现了stability。对这样一个平台,作为一种生态的构造形式的培训,像这样的模式可采用。
张亚勤:我觉得都会,各种不同的模式都会发生。
朱民:这里又回到了平行模型和垂直模型的区别,我看现在的大模型现在主要是做美国和中国,但美国的模型还是平行的,广义的模型多一些,中国现在来看是垂直模型比较多一些。
张亚勤:不能这么讲,我觉得都有。横向的模型很多,但是解决某一些问题的也都有垂直模型。
朱民:所以现在市场竞争的是横向模型,现在是“百模大战”,对竞争的结果活下来的人会支撑垂直模型。
张亚勤:对,可以这样讲。垂直模型、以及面向一些任务总是要做的。横向模型会帮你解决很多横向的问题,比如说自动驾驶长尾的问题。但是,它没法去替代垂直模型。咱们回到操作系统这个比喻,操作系统里面安卓和iOS也很强大,它上面有商店,但是很多Super APP还在上面。
你不可能操作系统做所有的这些应用,特别我们如果面向工业互联网,它更细分,更加深度。就像在PC时代,微软很强大,但也只能做个office,上面别的应用还是要靠生态。我经常讲,生态操作系统如果算一的话,它整个生态是乘100倍,在上面它的价值是100倍。
朱民:这个世界不可能只有唯一,一定是一个生态的,在上面会产生更丰富的应用场景,等等。
张亚勤:而且我觉得对以后垂直领域,或者对一些创业者其实是件好事。我看了很多言论说大模型出来之后别创业了,都被大公司做了。我认为不是这样,我觉得恰恰相反。比如,现在做某些面向某些任务的时候,我更容易做了。再比如说,过去我做一个什么事,我自己没数据或者数据很少,我需要收集数据,现在很多这些数据已经被预训练变成模型了,你就去靠那个模型,然后加上你自己这个领域的精准数据,或者结合你自己的模型,你可以开发应用出来。
这有点像云计算的时候,创业公司过去要买一大堆服务器,自己要有it方面的人。有了云之后,你买云服务就行了。你的算力、存储,你的网络能力都按需分配。所以,我觉得这是件好事,但创业公司可能要注意别做太简单的东西。如果太简单,大模型马上就帮你做了。创业者稍微要做一些有门槛的事。
朱民:创业的门槛高了。
本文为创业邦原创,未经授权不得转载,否则创业邦将保留向其追究法律责任的权利。如需转载或有任何疑问,请联系editor@cyzone.cn。