随着生成式AI在商业方面的应用更加深入,越来越多的企业希望利用向量数据库将自己的私有数据接入AI大模型,从而获得更好的数据安全性以及更好的AI性能。
但在实际应用中,企业用户会遇到一个问题:PPT、PDF、图片和网页等非结构化数据并不能通过向量数据库直接嵌入AI大模型。将大量的非结构化数据转化成AI大模型能够读懂的格式,其实是一个费时的大工程。根据调查,数据科学家在准备和管理数据上花费了将近80%的时间,而在企业中大约有三分之二的数据没有被使用。
一家新锐创业公司Unstructured希望解决这个问题,它们能将企业中的非结构化数据自动转化成AI大模型可以直接使用的数据格式(例如JSON格式)。它们的产品在2023年春季获得了超过80万次的下载,并且被GitHub上的2500多个项目使用。
近日,它获得了2500万美元的种子轮和A轮融资,其中种子轮融资由Bain Capital Ventures领投,A轮融资由Madrona领投,M12 Ventures、MongoDB Ventures以及LangChain创始人Harrison Chase、Weaviate的创始人Bob van Luijt也参与投资。LangChain(利用大模型构建程序的框架)和Weaviate(向量数据库)正是与Unstructured在AI技术栈上紧密相连的公司。
AI不能直接用非结构化数据?那就创立公司解决问题
Unstructured由Brian Raymond、Matt Robinson和Crag Wolfe共同创立。Brian Raymond创业之前是Primer.ai(一家为企业提供NLP能力的公司)的副总裁,Crag Wolfe是Primer.ai的架构和基础设施主管,Matt Robinson是拥有博士学位的数据科学家。

Unstructured团队
Brian Raymond在接受媒体采访时表示:“企业每天都会产生大量非结构化数据,当这些数据与大语言模型相结合,可以极大提高生产力。但这些数据是散乱而分散的,目前数据科学家们仍然必须完全手动的构建一次性的数据连接器和预处理管道。
我们在Primer.ai工作时,就反复遇到这个问题,为此,我们决定自己创业。现在,Unstructured提供了一种全面的解决方案,可以自动搜集企业内的非结构化数据,并转换成AI模型直接可用的格式。”
Unstructured在2022年7月创立,几个月后,ChatGPT的爆发颠覆了整个AI领域,生成式AI的热潮来临。企业使用AI的需求剧增,Unstructured在新兴AI大模型技术堆栈中成为关键组成部分,几个月内获得了超过80万次的下载,并且被超过100家公司和2500多个GitHub上的项目使用。
Unstructured的A轮融资领投方Madrona表示:“一个具有清晰的视野,深入的技术洞察力和商业直觉的创始人是非常罕见的,Brian就是兼具这些罕见品质的优秀创始人。我们对Brian从第一性原理出发的思考方式,与大型企业,公共部门,开发者社区的密切合作,以及对生成式AI技术环境的适应能力感到惊讶。
我们相信生成式AI会带来整个技术范式的改变,它是充满潜力的技术。Unstructured代表了市场的关键需求,如果没有它,我们可能将永远无法解锁AI的真正潜力,如果执行得当,将引领一个AI智能应用新时代。”
三个步骤,解决企业AI数据难问题
Unstructured对自己的定位是“ETL for LLMs”(ETL指数据整合),它正在建立一个企业级的提取、转换、加载(ETL)的数据整合管道,将企业的非结构化数据变得能被大模型使用。它允许各种规模的公司和组织最大化利用他们的数据,建立专门针对他们这些数据微调的大模型和聊天机器人。
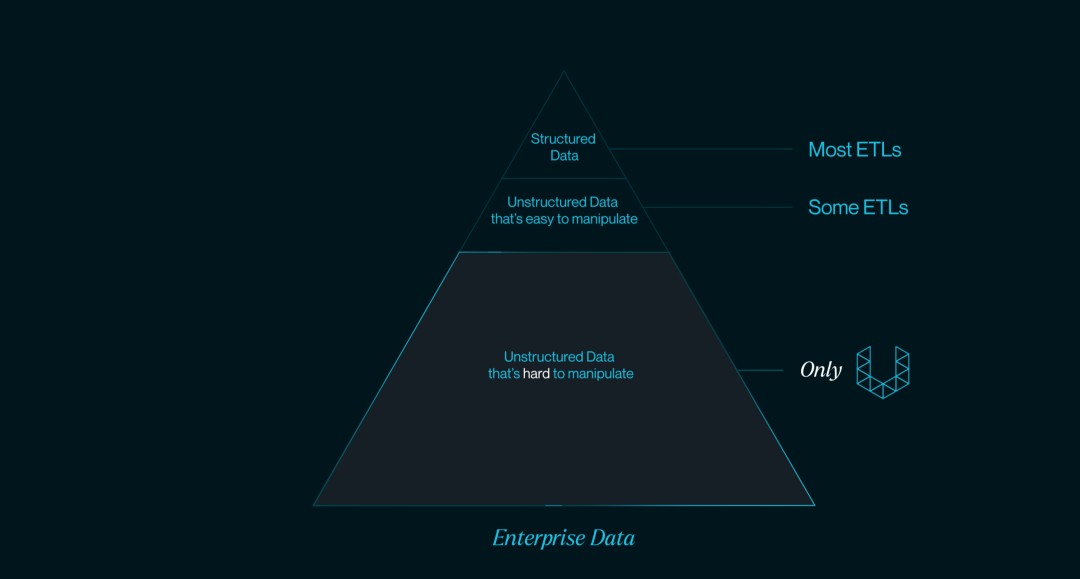
它表示,大多数ETL产品能处理的是结构化的数据,少部分ETL能处理比较方便整理的非结构化数据,而Unstructured能够处理数量占比最大的,难于处理的非结构化数据。
它的产品运作模式主要分为三步:
首先是抓取数据,通过企业级数据连接器,Unstructured能从企业的各种系统中安全地“提取”数据,包括本地文件系统、对象存储和数据湖。
第二步是数据转换与预处理,Unstructured能帮助企业把抓取到的非结构化数据“转换”成AI大模型能够直接读取的数据格式。它还发布了一个专用API,能处理20多种文件类型的转换。
第三步是加载数据,Unstructured与诸如LangChain(用于创建大模型应用的框架)和Weaviate(向量数据库)等公司的产品集成,这样AI大模型就可以直接使用经过转换的数据(通过向量数据库),开发人员也能用专有数据进行AI原生应用开发(通过LangChain)。
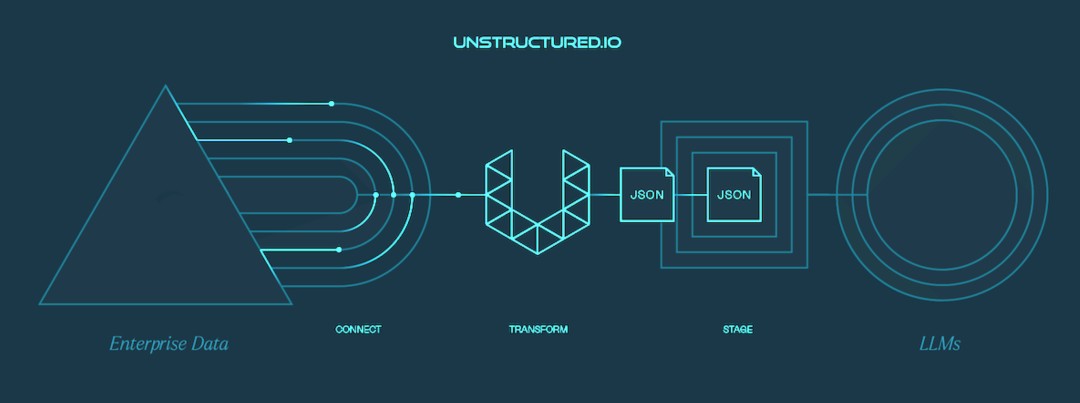
为完成抓取数据这个动作,Unstructured目前拥有15个数据连接器,可以从不同的软件中抓取不同格式的数据。
为完成数据转换这个动作,Unstructured训练了自己的“文件转换”AI模型,并与一些不同功能的现有AI模型进行整合,它们能处理约20种不同的文件。

在Unstructured的一个示例项目中,它使用了Pinecone的向量数据库(Chroma, Weaviate, Qdrant也有类似产品),OpenAI(各种开源模型也可以使用)的大模型,LangChain的编程框架(Llama Index也是同类产品),进行了一次10万页PDF格式文档数据的提取和转换。从示意图中,我们可以清楚的看到它在整个AI大模型技术堆栈中的位置和作用。
AI原生垂直应用新时代真的要来了
作为AI大模型技术堆栈中的重要组成部分,Unstructured不仅与下游的AI大模型,向量数据库,LongChain等连接,也与上游的AWS、Azure、Dropbox、Office和OneDrive等产品集成。
Unstructured创始人Brian表示:“公司将继续专注于解决影响AI系统的数据问题。”随着它在整个AI和数据生态系统里扎根越来越深,它也将在未来变得更重要。
两位投资了Unstructured的企业家投资人有一个共识:“Unstructured解决了构建AI原生应用最大的绊脚石:没有足够的优质数据。”
两周前,开源可商用的Meta Llama 2大模型发布(请参考这篇文章),我们又为大家介绍了指数级降低大模型部署成本的Replicate(请参考这篇文章),本周则是为企业解决AI使用非结构化数据问题的Unstructured。
可以发现,对于AI创业者,训练AI基础大模型的巨大算力成本已经不存在了,也不需要自建基础设施来部署模型,将企业私有数据接入大模型的数据来源问题也已经解决。
那么,我们可以看到一个清晰的趋势:AI原生垂直应用的浪潮即将到来,因为创业者不再需要是AI专家,也不需要为AI付出高昂的模型训练、部署、数据整理成本,只要对垂直行业有深度的认知和积累,就可以开始干,这对拥有众多优秀产品经理的中国,尤为利好。
本文由阿尔法公社原创。







