编者按:本文来自微信公众号 “娱乐资本论”(ID:yulezibenlun),作者:付梦珍,创业邦经授权转载。
“贫困山村里,没上过大学的女人们在喂养AI。”
“富士康工人流向AI标注厂。”
“跟AI打工,贫困县也能月薪7000。”
在“有多少智能,就有多少人工”的AI时代,有一批人通过采集现实世界的图像、视频、文字等信息,清洗标注后将数据转化为代码输送给机器,从事这份工作的人叫做数据标注员。
打开关于AI数据标注行业的新闻,我们随处可见上述标题。低门槛、劳动密集、高度程式化、标准操作流水线,成为了数据标注工人身上最大的标签特征。而在国际上,因为有大量的非洲肯尼亚人在做相关工作,他们又有一个灰色昵称,“肯尼亚人”。
而这,也与数据公司的甲方——百度、阿里等,致力于要用技术改变世界的大公司们形成了鲜明的对比。大洋彼岸,数据标注服务公司Scale AI市值73亿美元,彰显了数据公司的资本潜力,也让我们看到了数据公司走向百亿美金估值的可能性。
随着AIGC时代的到来,数据标注员的工作有何改变?上述新闻标签是否是他们的行业常态?数据标注行业现在存在哪些问题?未来又有哪些发展前景?更重要的是,他们展现了AI行业背后的什么样的困难?
带着这些问题,娱乐资本论走进了四家数据标注公司,发现了如下的行业现状:
VOL.1.标注行业对员工的素质要求越来越高,本科生占比高
VOL.2.兼职的标注人员中宝妈较稳定,更受欢迎
VOL.3.垂类行业的数据标注订单增多,对垂类标注人才的需求量增多
VOL.4.底层数据标注员的工资与最低工资标准类似
VOL.5.AI只带来了短期的订单增加,小型数据标注公司很卷
VOL.6.多数数据标注公司没有构建自己的数据壁垒
VOL.7.数据公司的发展趋势:①、利用AI技术降本增效 ②、专注于某一垂类的数据 ③、往产业链上游走,做数据采集、合成等
01本科生越来越多,宝妈更受喜爱,监狱不方便
“我们不是富士康的流水线模式。”
当被问及公司的员工现状时,几家数据公司都给出了类似的回答。
龙猫数据成立于2014年,累计服务了60余家主机厂和自动驾驶公司,为客户提供整体的数据解决方案。
今年AIGC爆火后,龙猫接到了很多图文标注、视频标注需求的订单,会有很多多模态应用场景,比如车内座舱的文娱软件等。龙猫副总裁胡邱飞向娱乐资本论指出“这要求标注人员能理解大模型的应用,而大模型会考察几乎所有领域的通识类知识。此外,标注内容要和客户的模型价值尽量贴近。所以这也要求我们找的标注人员绝大多数学历在本科以上。”
 龙猫公司一角
龙猫公司一角
针对垂直领域,龙猫则会配备专业领域人员,比如为数学相关大模型招聘会高等数学的人,“如果不是这专业的人,你根本看不出细节上的区别。”
成都的汇众天智总经理骆靖元也在AIGC浪潮后提高了对员工的素质要求,“三四年前对员工的素质要求还不高,但是现在甲方对质量和效率的要求提高了。公司之前90%是大专,现在本科占到了一半,甚至有研究生。”
2018年,做软件的丁一峻,在朋友的引荐下接到了阿里数据标注的订单,2019年创立了飞火大数据公司。之后,出于成本考虑丁一峻回到家乡创业做数据标注公司,“那时的数据标注行业确实能提供大量就业,洛阳数据局2019年的时候也牵头想做数据处理公司,招人好招,但交付难。”
 2019年做百度某数据标注业务项目截图
2019年做百度某数据标注业务项目截图
“数据标注本质是高级搬砖。”丁一峻向娱乐资本论指出,“有标注需求的多是大公司,现在很多标注公司会外放做不过来的订单,这就让市面上很多没跟甲方深度捆绑的公司,接的订单都特零碎。这种订单一是边缘化业务,比如小语种。二是时间周期短的业务,很考验外部公司的交付能力。”
这两类订单,也倒逼着丁一峻要提高对员工素质的要求。这期间,丁一峻尝试过和学校监狱合作,相继作罢,“学校要考虑领导、辅导员各种利益分配,监狱对网络要求高,不如找全职。”
 飞火大数据公司一角
飞火大数据公司一角
综合原因下,大部分的数据公司更倾向于招聘兼职人员。沈阳正午数据公司人事小苏接受河豚君采访的前一天,刚在Boss直聘上发了招聘兼职的通知,“行业本身利润有限,全职成本太高了,根本就不能实现。”
“我们招人基本要求大专以上,发了以后有上百人联系我,但是很多人没经验。”小苏招聘时,会和兼职强调对数据保密性的要求,“不知道是不是受网络的影响,很多人戒备心很重,听到要保密就不做了。但我们公司有良心,必须强调保密。”
杭州景联文是一家从事数据采集标注、数据融合挖掘的公司,现有1000多位全职标注人员,其CEO刘云涛向河豚君透露,“标注项目难度越来越高,要求标注员的学历和专业知识水平越来越高,比如语言标注团队,要求会各种小语种。医疗标注,需要医学院毕业的学生。”

龙猫则是全职兼职两手抓。胡邱飞透露,“我们现在线上注册用户400多万,活跃全职的1万人左右。”线上之外,龙猫在西南地区做了线下标注基地,“那边高校多,学生素质也更高,员工500人左右。”
龙猫的全职运营会了解兼职的情况,“我们更喜欢用没有全职工作的群体,比如宝妈,她们时间充沛,更好管理,也更稳定。”
整体来说,如今数据行业的标注人员发展如同美团般发展成了全职、服务站、众包等阶梯式的人力模式。胡邱飞透露,“我们线上众包是强管控,最终交付结果都是计件的。”
小苏介绍,目前公司兼职的员工大概两三千,常驻人员1000左右,流失率一半。丁一峻透露,“基础的标注员往往都是属于地方上的最低工资标准,三线城市两三千左右,质检员和项目经理,能到七千左右。”
02层层外包下,标注公司活少钱少风险高
“太卷了。”
这几乎是数据公司们共同的心声。
“我们现在就像河南的食品代加工厂一样,品牌是别人的,工作相当于帮别人养孩子。”丁一峻的公司高峰时有两三百人,现在公司只有40多位员工,“老客户的需求还在,能维持正常运营,但这种单子很鸡肋,一个月几百几千跟办公室采购差不多,利润太低,项目体量也不稳定。数据行业缺乏像苹果、特斯拉一样需求稳定的工厂。不然我也不想裁人,有活还需要找外包。”
骆靖元指出,AIGC爆火后自己招人和以前相比省去了科普人工智能的环节,但在接活上更卷了,“大公司有定期筛选的机制,比如说这批我需要10家公司。那我就从100个里面筛选,其中哪两三个不合适,我再动态替换。这使得一些公司不断报低价,恶性循环。”
为了接到订单,丁一峻一直在努力降本增效,“为了提高效率,我们开发了AI工具,之前2D拉框要8分一个,现在降到了5、6分,操作更便捷。质量上,如果客户不想要目标物低于某像素值的,工具直接调数值,标注员就不用标了。”
但是这种工具标注公司基本只能自用,“同行有能力买的,自己有开发的实力。没开发实力的,出不起这个钱。”说着,丁一峻给我发来了网上开源的标注工具,“每家平台都差不多,都是基于labelme的底层逻辑。早几年能打个信息差,卖平台赚点钱,现在不行了,大家都知道套路,直接上源码加个UI就成产品了。”
 某标注工具图
某标注工具图
“今年2月GPT刚火的时候订单多了一些,那时大公司的目的更多是为了割韭菜炒股价。后来这些AI大公司发现变现难,七八月份就很少在数据标注上投入了。”保定的数据标注老板周三体说,标注公司遇到的困难,仿佛也印证了AI潮冷去的某种现实,“AI公司的客户很多还是G端,根本不在乎AI能力,更在意能不能喝酒、能不能垫资”。
为了接活,周三体努力降低成本,“2D拉框最早是1毛5一个,现在降到了8、9分一个框。”
景联文在努力将非标准化产品标准化,现在将2D拉框标注项目的成本降低了50%。
打开天眼查搜索数据标注公司,我们也能发现大部分的公司经营所在地都在河北、山东、河南等人口大省,这与当地劳动力密集且廉价息息相关。“大厂会把业务承包给有资历和实力的公司,这种公司再外包,到我们价格很低了,还需要垫款,压力很大。”周三体说时叹了口气。
回忆起2017年创业的日子,骆靖元说那时借着自动驾驶行情数据行业很火,订单像雨后春笋一样地涌现,“像百度做了语音采集,高德、讯飞会再做一遍。算法都没变,标注都是新瓶装旧酒,同样一批人脸识别的图片,A公司做完B公司做,之后C公司再做,我们始终是在给别人做嫁衣。”但这样的日子也好景不长,如今订单量变少,“人员迅速增加后又会有断档期,大部分公司死在了断档期里。”
被问及是否觉得公司的运营模式是新时代的数据工厂时,丁一峻认为,“AI的产品线不像工厂那么完善,缺乏法律和社会面的支持,比如版权、数据安全。”
丁一峻曾承接过一家证券公司的标注工作,“刚好有一家标注员是这家证券公司的用户,他提出了抗议,后来私下花钱和解了。谁采集数据,出了问题谁负责,所以一般我们也不会过问数据来源情况。”
技术壁垒低、政策法规不健全、订单量少且不稳定,数据行业面临着多种困境,这也逼着其从业者寻找新的转型发展之路。
03被AI代替?还是用AI起飞?
为了降本增效,龙猫研究了AI加持下的数据标注管理系统,“自动驾驶上节省了40%,AIGC在探索引入GPT等大语言模型校准标注结果。作为机器和人的交叉验证,保证输出的一个质量。因为人会有波动,机器更加稳定,偏差小。”
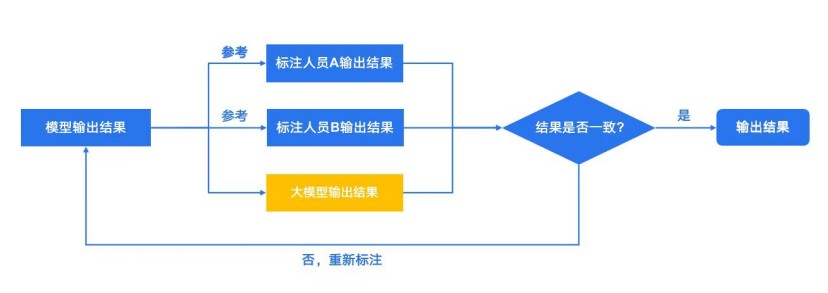
此外,龙猫在尝试通过AI技术省去标注环节,直接进入到审核和质检环节。
高质量语料,尤其是私域数据,是做好数据标注的关键,AI在仿写改写上的潜力,让人看到了其在合成语料上的潜力。“根据最新的生成式AI管理办法,用户拥有自己5张照片的版权,但5张照片合成后生成的数据版权属于合成方。”胡邱飞据此出发,在探索数据拟合向业务,目的在于拥有数据的所有权,标注后多次复售数据包。
AI创业者周晓明指出,“AIGC赋能合成数据,能够解决真实数据获取难、获取成本高、多样性不足、缺乏隐私保护等痛点问题,替代真实是大势所趋。”
对此,丁一峻则未敢尝试,“AIGC合成数据需要看政策,现在是灰色地带,好不好获取,就看胆子大不大了。谁也不知道未来会不会出爆款,有比拟真实数据的内容出现。”
此外,龙猫也在探索获取高质量数据的新方式,打造公司壁垒,胡邱飞说,“国外出现的一种趋势是用户主动售卖自己的数据,让数据公司得以绕开原始数据的厂商垄断的局面。我们也在想,怎么让那些有时间、素质又高的人做数据输出和标注,比如说通过做题的方式,让他们小程序上答题赚钱。”
“数据标注是自我淘汰的行业,AI可以通过模型优化做部分标注工作。发展到最后,这个行业可能只会剩下质检员这些岗位。”丁一峻为了应对变化,将公司从洛阳搬到了工业配套更完善的苏州,做数据采集车业务,“我们要给甲方提供硬件采购和数据服务的整套方案,这样甲方对我们的依赖度才能更深。”
 AI作图 by娱乐资本论
AI作图 by娱乐资本论
景联文则选择了深耕垂类赛道,专注于教育和医疗领域,刘云涛透露,“教育方面,我们手上有3亿道从小学到职业教育的题,格式统一,解析维度包括专题分类、分析过程、考点解析、解答过程、教师点评等。现在大模型号称百模大战,至少有60家都要买我们的题库。”
医疗方面,景联文积累了400TB的医学资料数据库和三甲医院的专家的病理数据。“我们两年前开始拓展标注场景,选了医疗赛道,不管经济多不景气,医疗始终有存在的意义和价值。”
值得一提的是,龙猫AIGC业务线负责人李亚向娱乐资本论透露,龙猫正在打造自己的垂类大模型,“大模型一是做辅助标注,读懂题目后给答案让人选。第二是做全自动标注,AI直接出结果。这种情况我们会做双盲的实验,比如一个答案用三个标准做一遍,里面我们会拆一个一个人或者两个人用这种形式做,这样不需要再做抽检和质检,有些项目我们已经用GPT交付了,准确率方面达到了80%多,与人工接近。”
对市场规范化的呼吁,成为了不少数据标注从业者的心声,刘云涛指出,“未来,怎么让数据流通合规化、安全化是很大的问题。现在很多城市在建立大数据交易中心,是积极的信号。”
艾瑞数据的人工智能数据报告指出,三年后,中国人工智能的数据治理市场规模预计将突破百亿。
但更现实的问题是,吐槽中文语料库差的新闻屡见报端,大量的中小型数据标注公司正在卷生卷死,大批数据标注公司的业务产品,在批量化、利润率、风险性方面甚至不及富士康产品,映照到市场上的,则是逐渐遇冷的大模型市场以及越来越像“高科技施工队”的中国AI商业环境。
当我们试图寻找解决之道时,骆靖元回忆其工作多年感受时的话也许是最好的答案,“对我们同事来说,当看到应用落地的时候,还是比较欣慰的事情。虽然工资低,但终归是做了点有用的事情。”
“数据是AI走向智能的基础,少开点发布会炒股价,多投点钱在标注上才是正事。”采访接近尾声时,周三体发来了这句话。
本文为专栏作者授权创业邦发表,版权归原作者所有。文章系作者个人观点,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。







