编者按:本文来自微信公众号 新硅NewGeek(ID:XinguiNewgeek),作者:董道力,编辑:张泽一,创业邦经授权转载。
硅基君这几天可算是被OpenAI的视频生成模型Sora狠狠的刷了一通屏。
明明还没有正式开放,但在国内外社交平台上,几乎每一个Sora放出的Demo视频都能被翻来覆去讨论。
大家对Sora的崇拜,甚至到了拿一个上古时代的互联网经典视频出来,都说它是Sora生成的,还要贴心的配上一个简单的Prompts。
在没有人关注的小角落里,谷歌发布的Gemini 1.5 PRO没能溅起一点水花。
有人猜测,OpenAI如此匆忙的发布Sora的演示视频,就是为了向世界证明OpenAI才是AI行业的突出公司,因为就在几小时前,谷歌才发布了Gemini 1.5 PRO。
从热度上来看,谷歌输的一塌糊涂。
当然,和以往一样,OpenAI发布的Sora,目前只针对部分科学家和艺术家开放,普通人想用到Sora话不知道要什么时候了。
但这一点也不影响全网对Sora的热烈讨论,Sora发布后的48小时内,科技大佬、卖课的、炒股的、创业的都“疯了”。
首先是科技大佬们对Sora发表了自己的看法。
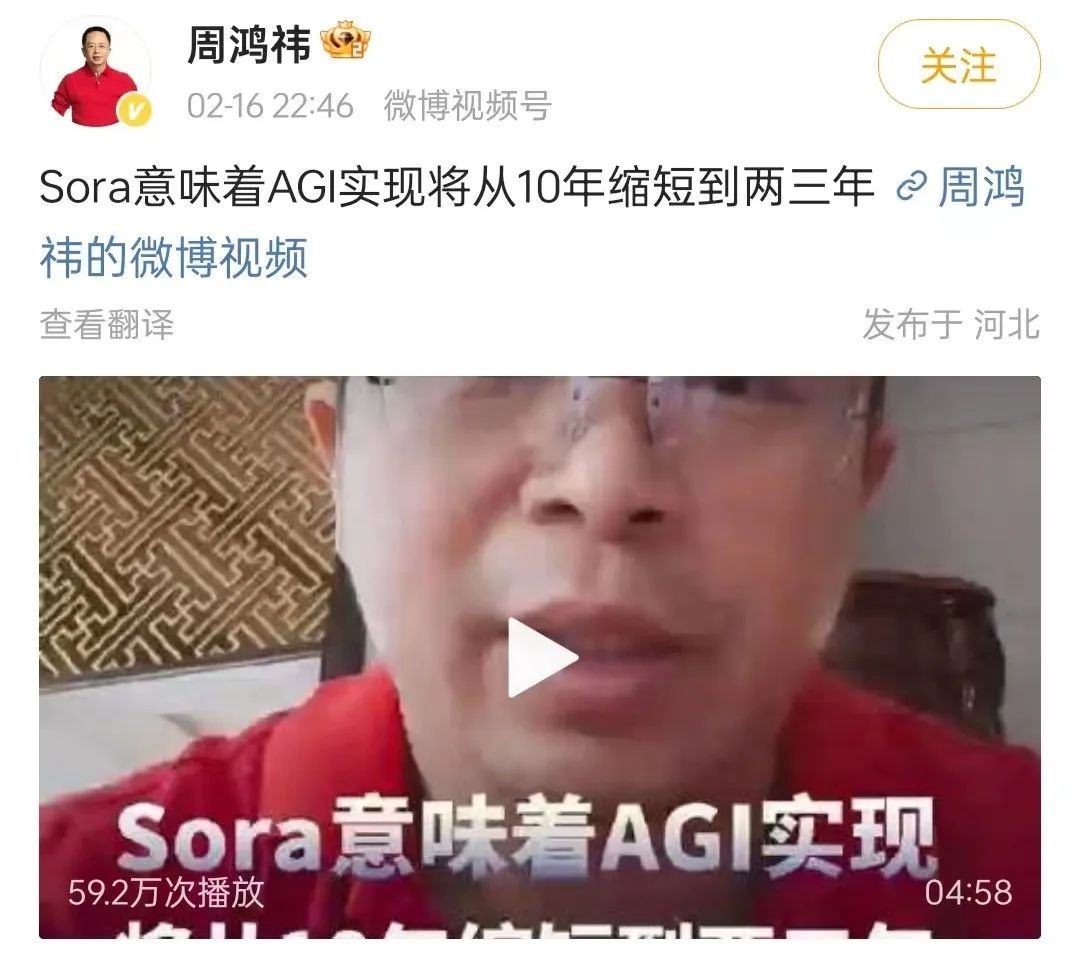
360总裁周鸿祎认为,Sora意味着AGI实现将从10年缩短到两三年。OpenAI的Sora可以吊打 Pika和Runway,原因在于人才密度。OpenAl利用它的大语言模型优势,把LLM 和Diffusion 结合起来训练,让Sora实现了对现实世界的理解和对世界的模拟两层能力等等。
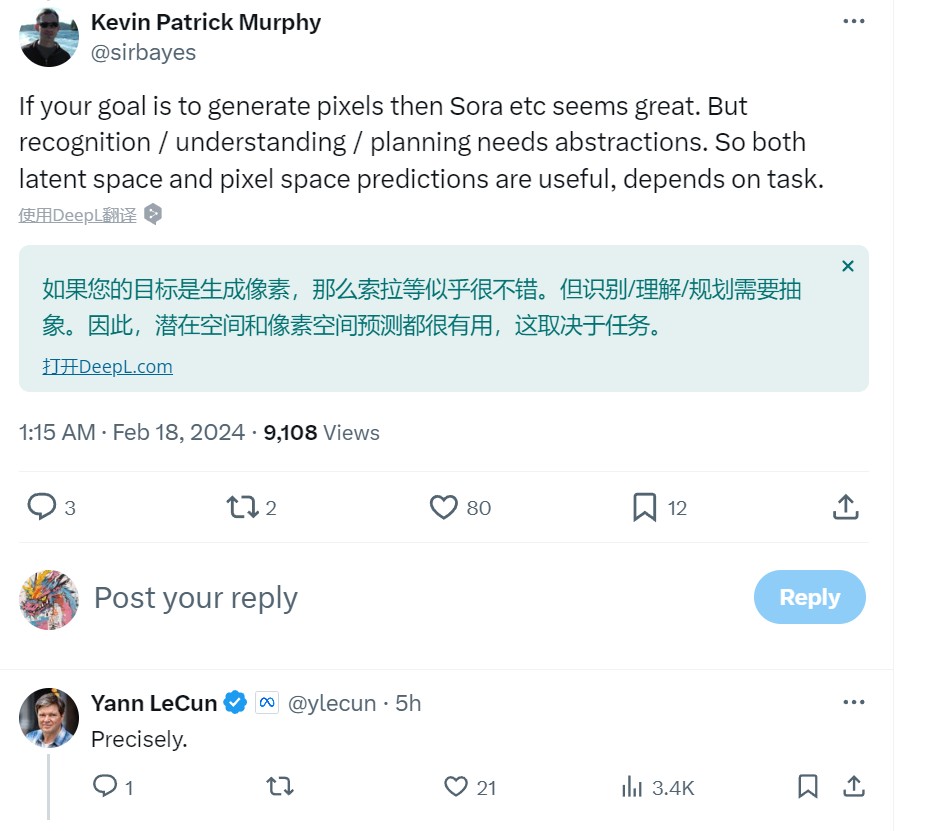
Meta首席AI科学家杨立昆并不怎么看好Sora,他在twitter上表示一个AI模型可以生成逼真的视频,但并不代表这个AI可以理解世界。
与周鸿祎和杨立昆的长篇大论不同,马斯克简单明了:人类要完蛋了。
股民们在OpenAI发布Sora后,感觉下一个ai风口就在眼前,有机构连夜盘点了国内视频生成相关的公司,甚至出现了Sora概念股。

与股民的热情不同,一些影视从业人员表示,自己的工作岌岌可危。
据蓝鲸财经报道,中国香港青年导演朱智立表示“它(Sora)对电影行业的影响只是一个时间问题,因为它已经把画面做到非常真实、有细节,包括一个女人在东京街头的画面,连脸上的雀斑都能做到非常真实。”
“Sora对宣传片、广告片的影响会更大”朱智立觉得“电影还有剧本、情节、台词等复杂因素,而在广告、宣传片行业,冲击可能会更快到来。如果提示词可以细节到分镜,那AI不仅仅是帮助导演画分镜和视觉参考图了,而是直接可以做成更高效的动态分镜预览,或者等技术更成熟时可以直接用来做成影视作品。”
无论是科技大佬的分析预判,还是股民的热情,影视从业者的担心,硅基君都表示理解,但唯一不合理的就是,Sora刚发布,连排队内测都没开启,OpenAI还没靠Sora赚到钱,就有人开始卖课了?
技术来来去去,卖铲子永不过时。

话说回来,Sora之所以能引起广泛的讨论,原因在于它生成的视频质量真的太好了。为什么Sora效果那么好,技术上有什么特别的吗?根据OpenAI发布的Sora技术白皮书,我们可以略知一二。
先上一个大瓜,Sora的视频生成模型框架,很可能是谷歌DeepMind之前的论文成果。
简单来说,Sora模型效果很好的关键在于,OpenAI训练的时候,将扩散模型(diffusion model)和transformer相结合。
OpenAI训练GPT这类大语言模型的时候,把句子拆分成tokens,放到transformer进行训练。在Sora中,OpenAI将不同尺寸、分辨率的视频拆分成patch,把patch当作tokens放到transformer进行训练。训练完成后再通过解码,把tokens“渲染成”人们可以看得懂的像素。
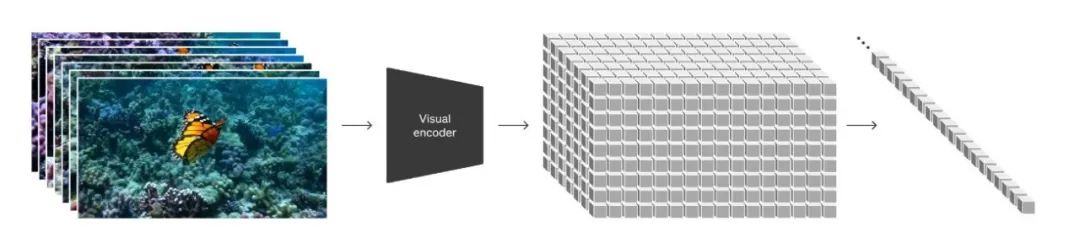
这一技术,来源于谷歌DeepMind和谢赛宁的论文成果。


硅基君搜了一下这篇论文的另一个作者William Peebles,他现在居然就是领导OpenAI Sora项目的负责人!
好家伙,这手背刺玩的6。

硅基君又往前找了一下,不知道大家还记不记得年初谷歌发布的videopoet这个视频生成模型。videopoet也是一个基于大语言模型生成视频。
其中的MAGVIT v2技术源于论文《Language Model Beats Diffusion: Tokenizer is Key to Visual Generation》,从论文名字中,我们就可以看到,作者对OpenAI Sora采用的模型框架的讨论。
当然,OepnAI基于谷歌那篇论文技术的基础上,还做了不少创新。据Sora的技术白皮书透露,OpenAI利用GPT训练了一个模型,将简短的用户prompts转换为更长的详细prompts,从而让生成的视频更符合用户需求。这一技术早些时候用于DALL·E 3 上。
比如说,咱们输入“带笑容的女人视频,时尚风格”,在Sora眼中可能就会变成:
“走在时尚之都巴黎香榭丽大街上的女人笑得非常开心,眼睛里充满了喜悦。她穿着时髦的服装,凸显了她的曲线,头发也梳得恰到好处,衬托出她的容貌。”
在训练数据采样方式上,OpenAI更加开放,以往的视频生成模型的训练数据大多是切割成方形的,但Sora直接采用原生视频数据进行采样。这以方法,也让Sora拥有了在保证主体一致的情况下,生成不同分辨率视频的能力。
比如技术白皮书中展示的乌龟和海底场景,仔细看不同尺寸的视频中,乌龟还是那个乌龟,海底的环境也很类似。

除了以上这些创新,OpenAI在训练Sora上,也遵循了大力出奇迹的传统,也就是加计算量。
可以发现,4倍计算量下的Sora生成的视频和pika、runway、videopoet在效果上类似。但当计算量来到32倍后,Sora生成的视频质量有明显的提高。
大模型真的是一个大力出奇迹的行业吗?怪不得OpenAI的CEO奥特曼想花重金(7万亿美元)投资芯片了。
看到这里,不知道观众老爷们有没有这样的感觉,OpenAI发布Sora爆火的背后,满满都是谷歌的影子。
其实这样的事情已经不是第一次发生了。
在《这就是ChatGPT》一书中,介绍了发现大语言模型在规模数据后产生涌现现象的谷歌研究员Jason Wei跳槽到OpenAI,并抢先Anthropic Claude一步,推出ChatGPT火遍全网的故事。
类似的故事还有不少。
比如,谷歌推出transformer这一奠定大模型基础的技术后风光无限,但却被OpenAI用大规模训练数据截胡,率先推出了大语言模型GPT3。从此人们说到大模型,首先会想到OpenAI。
之后,掀起AI浪潮的ChatGPT,其前身InstructGPT用到的 instruction tuning技术,也是谷歌与21年发表的,但谷歌直到22年才开始重视。
如果把谷歌和OpenAI拟人化,谷歌像一个清高的科学家,不断突破创新,带来一个个新的技术。而OpenAI则像一个项目经理,哪个技术好就拿来用了。
可以说,OpenAI站在谷歌的肩膀上,用谷歌的技术刷屏。
本文为专栏作者授权创业邦发表,版权归原作者所有。文章系作者个人观点,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。







