编者按:本文来自微信公众号 新智元(ID:AI_era),编辑:桃子,创业邦经授权转载。
MIT天才博士一毕业,火速加盟OpenAI前CTO初创!
最近,肖光烜(Guangxuan Xiao)在社交媒体官宣,刚刚完成了MIT博士学位。
下一步,他将加入Thinking Machines,专注于大模型预训练的工作。

评论区下方,英伟达科学家、xAI研究员、UCSD等一众大佬,为他本人送上了祝贺。
上下滑动查看
清华双学位学霸,MIT博士开挂人生
打开他的个人主页,多元而充实的经历便映入眼帘。
肖光烜本科毕业于清华大学,拿到了双学位,主修的是计算机科学,金融学是第二学位。

在此期间,他获得了清华大学综合优秀奖学金(2019)、全国大学生数学建模竞赛(CUMCM)一等奖(2020)、国家奖学金(2020)、清华大学「未来学者」奖学金(2021)等多项奖项。
他曾于2020–2021年作为访问生(Visiting Student),前往斯坦福大学计算机系开展科研工作。
2022年,肖光烜加入MIT攻读博士学位,导师为韩松(Song Han)教授。
个人研究方向聚焦于:深度学习的高效算法与系统,尤其是大规模基础模型(Foundation Model)。
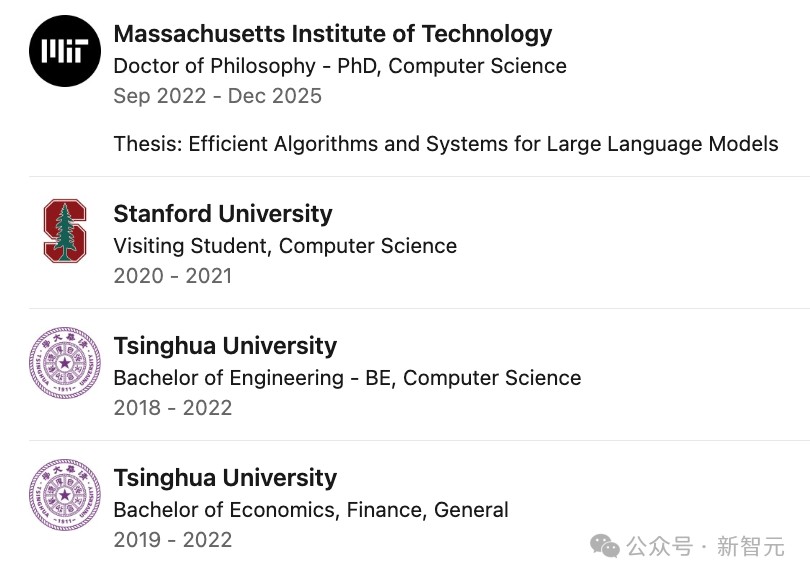
他于2022年9月至2026年1月,在MIT EECS担任全职研究助理(Research Assistant)。
读博期间,肖光烜曾多次进入全球顶级科技大厂从事前沿研究实习,具备了丰富的一线工业研发的经验。
2023年,他曾加入Meta实习,研究方向为「流式语言模型的高效注意力机制」,相关成果发表在arxiv上。

论文地址:https://arxiv.org/pdf/2309.17453
2024年2-5月期间,他作为英伟达实习生,研究方向是为长上下文大语言模型推理加速。
他和团队提出了DuoAttention,结合检索与流式注意力头,实现高效推理。
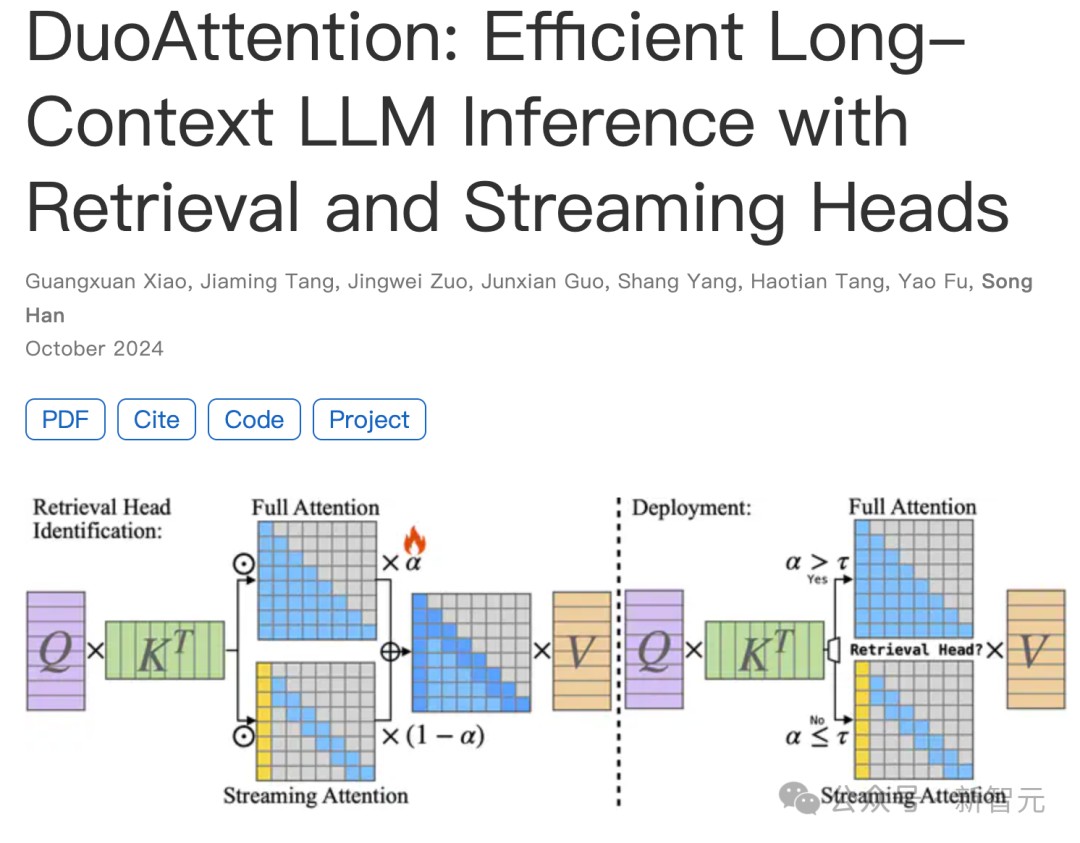
论文地址:https://research.nvidia.com/labs/eai/publication/duoattention/
随后,他又参与了多项核心研究项目,其中包括:
XAttention:基于反对角评分的块稀疏注意力机制
StreamingVLM:面向无限视频流的实时理解模型
FlashMoBA:混合块注意力(Mixture of Block Attention)的高效优化
值得一提的是,肖光烜在研究之外,还有丰富的兴趣爱好,比如足球、乒乓球、围棋、钢琴。
他曾担任所在院系足球队的队长兼先锋,贝多芬的作品是个人最爱。

一篇博士论文,破解LLM三大难题
比起耀眼的履历,肖光烜的博士论文本身更值得深入研析与拆解。

不得不承认,如今大模型已经无所不能,但它们依然太贵了。
显存爆炸、推理太慢、长上下文直接OOM(内存溢出),这是几乎所有LLM工程团队每天都在面对的现实。
Efficient Algorithms and Systems for Large Language Models这篇论文,给出了一个罕见的、从工程到理论、从算法到架构的完整答案。
论文中, 他们提出了SmoothQuant,解决了一个长期困扰工业界的问题——激活值异常(activation outliers)。
SmoothQuant通过一个巧妙的数学等价变换,把量化难点从「激活」转移到「权重」。
结果,它实现了首个在十亿级模型上W8A8无损量化,无需重新训练,显存更小、推理更快。
针对超长序列的处理,作者在StreamingLLM中发现了「注意力汇点」(attention sink)现象——
即使没有任何语义,初始token会被后续token持续关注。这些token的作用不是「理解」,而是数值稳定。
结果,实现了常数内存的流式推理,模型上下文长度从数千token扩展到百万级。
更进一步,他们又把这一思想推广到多模态,StreamingVLM可以在保持时间一致性的同时处理长达数小时的视频内容。
对于超长上下文场景,团队又提出一个互补方案,分别针对不同的性能瓶颈。
KVCache太大,采用DuoAttention
注意力头本身就有分工:少数负责「全局检索」,多数只看「最近上下文」。
DuoAttention用混合策略,大幅降低显存,却几乎不掉性能。
预填充(Prefill)太慢,采用XAttention
利用反对角线评分机制,仅识别、计算必要的注意力块,从而实现显著的加速效果。
论文的最后,并没有止步于「优化现有模型」,通过对MoBA(块混合注意力) 的信噪比分析,作者证明了:
理论上,block越小越好。
但现实是,GPU不答应,于是有了FlashMoBA,一种定制化的CUDA内核,使小块架构在实践中可行,并实现了最高可达9倍的速度提升。
这篇论文的价值在于,构建了一整套高效大模型的完整框架,既回应了当下的现实挑战,也为下一代计算高效、普惠可及的AGI奠定了基础。
平均350万年薪,碾压OpenAI
最后来到一个大家比较感兴趣的话题——薪资。
去年,硅谷人才争夺战激烈,BI一篇独家挖到了Thinking Machines(TML)给员工们开出的薪资——
基础年薪高达50万美元(约350万元)。
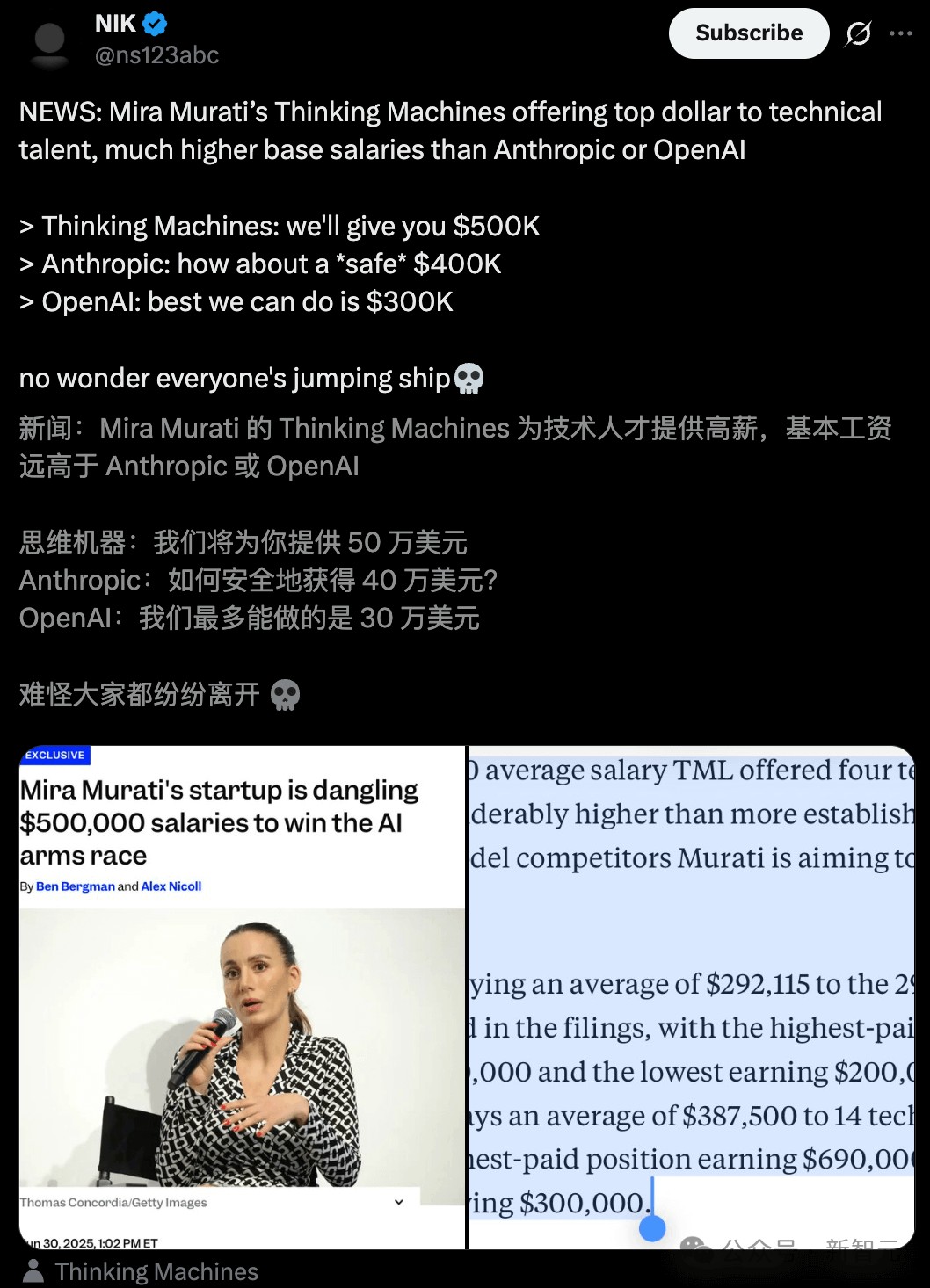
据BI获取的招聘数据,TML向两名技术员工支付了45万美元的基础年薪,另一名员工的年薪则高达50万美元。
第四名员工被列为「联合创始人/机器学习专家」,其年薪同样为45万美元。
这些薪酬数据,来自2025年第一季度,早于Murati以100亿美元的估值,成功完成20亿美元的种子轮融资。
总体来看,TML为这四名技术员工提供的平均年薪达到462,500美元。
相较之下,TML明显高于业内更为成熟LLM公司——
OpenAI在相关申报文件中列出的29名技术员工,平均年薪为292,115美元。
其中最高薪资为53万美元,最低为20万美元。
Anthropic向14名技术员工支付的平均年薪为387,500美元,薪资区间在30万至69万美元之间。
虽然比起Meta疯狂的超1万亿美元薪酬还差得远,但这一水平也在硅谷数一数二。
果然,21世纪最贵的还是人才。
参考资料:
https://x.com/Guangxuan_Xiao/status/2008779396497502337
https://guangxuanx.com/
https://scholar.google.com/citations?user=sRGO-EcAAAAJ
https://www.eecs.mit.edu/eecs-events/doctoral-thesis-efficient-algorithms-and-systems-for-large-language-models/
https://www.businessinsider.com/muratis-new-ai-startup-salary-technical-talent-2025-6
本文为专栏作者授权创业邦发表,版权归原作者所有。文章系作者个人观点,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。







