
作者丨Luka
编辑丨刘恒涛
图源丨灵初智能
今年4月,灵初智能发布了两款“具身大脑”模型,分别是Psi-R2和Psi-W0。在艾伦AI研究所发起的MolmoSpaces榜单上,Psi-R2超越PI、DreamZero等国际模型,位列全球第一。
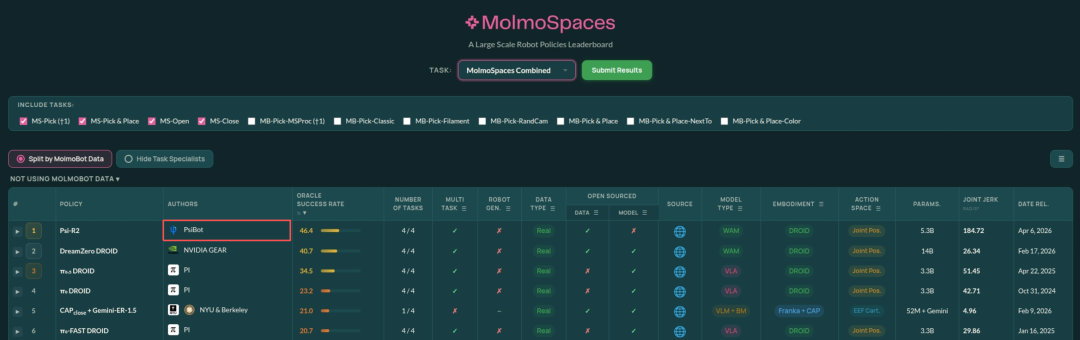
这两款模型的独特之处在于,从一开始就坚持用“人类数据”进行训练,而不是行业主流的仿真或遥操方式。这种更贴近真实世界的高质量数据路线,使模型具备了更强的泛化能力。目前,灵初智能已积累近10万小时人类操作数据,并开源了全球最大的人类手部操作全模态数据集。可以说,在人类数据路线上,灵初智能稳居行业前列。
这一技术路线近期获得海外关注。5月7日,摩根士丹利在《人形机器人前沿报告》中,将灵初智能视为中国机器人“大脑阵营”的核心代表之一。
“我们的目标,是成为基于人类数据的具身大脑,在海外市场重塑具身智能的技术生态。”CEO王启斌近日表示。

灵初智能CEO王启斌

率先押注“人类数据”
在具身智能发展初期,业界有两种数据采集方式。一种是仿真模拟采集,即在虚拟环境中模拟机器人运作,生成大量仿真数据用于模型训练。另一种是真机遥操作,即通过操控真实机器人设备,直接采集实际运行数据。
这两种方式各有优势。仿真采集能以较低成本生成海量数据,真机遥操作则胜在数据真实性。然而,两种方法实际效果都不理想:遥操作是“机器教机器”,无法复现人类的感官与纠错能力;而仿真数据离真实环境更远,碰上柔体、精细接触这些场景,模拟不到位。
归根到底,机器生成的数据始终与真实情况存在一定距离,原因在于,这种生成方式并未从底层认识到人类完成动作的机制。
实际上,人类能完成这些物理操作,背后有一套独特的流程。比如,会把复杂动作拆解开,用眼睛观察、用手触碰尝试,再进入精细操作,整个过程是感知与动作的循环。即便出现意外或错误,也能实时纠正。这正是人类多感官协同与自适应能力的体现。
如果将人类在这一流程中的多模态信息捕捉记录下来,用于机器学习,那么模型训练就能学习、理解到人类的操作逻辑。这类数据被称为“人类数据”,是当前具身智能模型最需要、但最难获取的能力。
灵初智能联合创始人陈源培很早就意识到,“人类数据”是训练通用模型的“最高质原料”。在2024年末的机器人顶会CoRL上,他提出:人类行为可以被捕捉并转化为机器人的训练数据。陈源培用人类手部数据训练具身模型的早期探索,也成为灵初智能押注人类数据路线的重要技术来源。
如今,灵初智能坚持以人类数据为核心、仿真数据为辅助,正打造基于人类数据的具身大脑,并为此确立了“无本体数采”的方式——让人类佩戴设备执行动作,从而直接、纯粹地采集操作数据。
具体而言,灵初智能自主研发了全球首个灵巧手真实世界数采引擎——Psi-SynEngine。人类穿戴了数据采集手套后,在真实的劳动场景中,便可同时采集视觉输入、手部关节角、触觉及腕部位姿等多模态数据。这些数据经过云端平台的质检、审核等自动化管线处理后,再用于训练具身模型。
用人类数据训练具身模型的趋势日益明确。自2025年下半年起,越来越多头部公司开始转向人类数据采集。而灵初智能,在这一方向上已经积累了近10万小时的人类手部操作多模态数据。今年,他们的目标是冲击100万小时,让具身智能模型跨越质变门槛的数据量级。
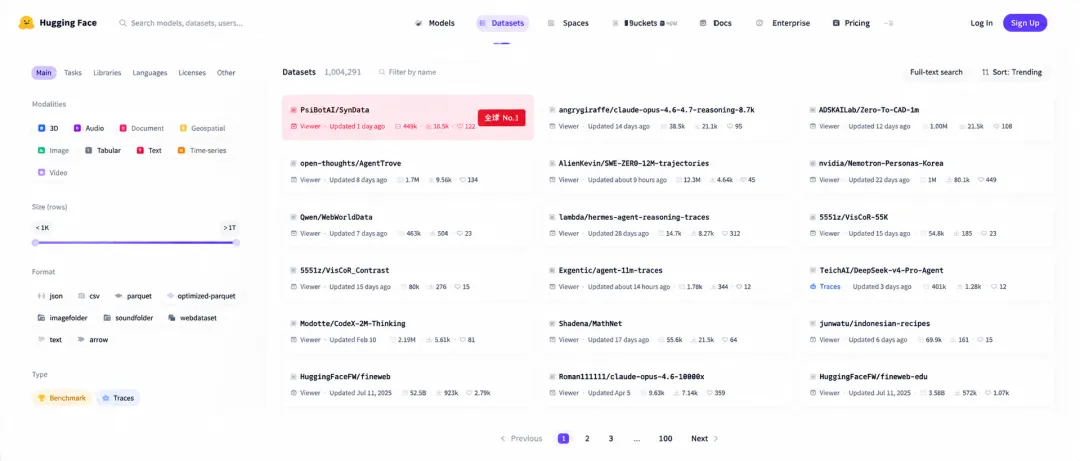
全球最大的开源 AI 社区 HuggingFace 上, 由灵初智能开源的SynData 数据集冲上了 Trending 榜全球第一
灵初智能CEO王启斌表示,灵初智能希望成为“人类数据标准的制定者”,正尝试通过开源的方式推动行业标准的形成。他指出:“我们已经开源了全球最大的人类手部操作全模态数据集,首批开放1000小时。接下来,我们还将结合行业力量,共同推动相关Benchmark的建设。”

基于10万小时“人类数据”的具身大脑
今年4月,灵初智能发布了两款“具身大脑”模型——R2和W0。这两款模型均基于10万小时的人类数据训练而成,在实际运行中相互配合,共同完成决策与评估任务。
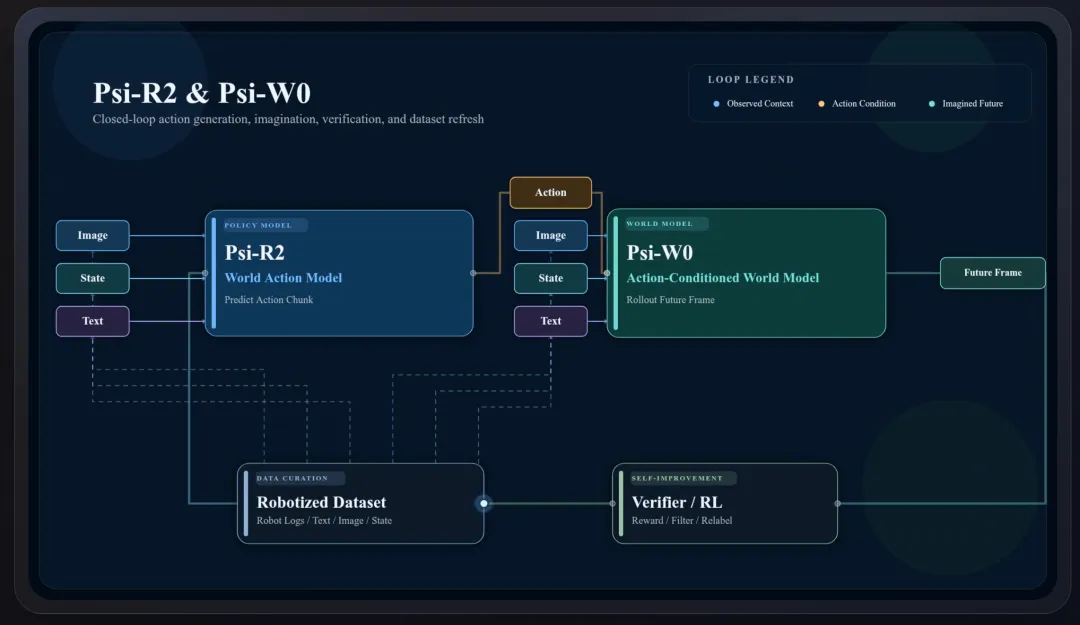
R2是一个策略模型,被部署到机器人身上,负责执行动作。这是全球首个以10万小时量级人类数据预训练的世界模型。在MolmoSpaces榜单上,R2排名全球第一,超越了PI、DreamZero等国际模型。
W0是一个仿真器,其核心功能是评估和优化R2模型。它通过模拟真实物理环境来提供反馈:当R2在W0中执行一个动作后,W0会计算出相应的结果,并将该结果与预设的目标状态进行比对。若两者一致,则判定动作成功;若不一致,则判定失败。W0据此向R2发出反馈信号,驱动其调整策略。
王启斌表示,“这个过程就像,机器人拿一个线束,插入到计算机的Type-C接口里。如果最后的状态达到预期,就说明成功;如果没有,就在W0里重新做强化学习,不停地试错。”
为了让模型理解物理世界的边界,灵初智能对W0做了一个特殊设计,注入了30%的失败数据,帮助W0学会判断“什么情况会出错”。
与行业主流的单模型架构不同,灵初智能选择将R2与W0分开设计。王启斌解释,不合并的原因在于,两者的任务不同:R2只关注“成功是如何发生的”,其训练数据必须是成功的案例;而W0恰恰需要大量失败数据,用以学习“世界的物理规律”与“反事实推演”。
在模型能力上,灵初智能设定了阶段性目标:今年年中实现长程任务成功率40%-60%,具备更强的zero-shot泛化能力;年底结合语言模态,让模型能够根据语言指令自主进行任务规划。
王启斌强调,灵初智能的定位始终是“大脑公司”,所有的数据、硬件产品均为模型服务。公司于2025年推出了拥有21个自由度的灵巧手产品ψ-SynHand,但这款灵巧手不会单独出售。“我们最关心的不是灵巧手本身,而是模型的进展。”灵巧手等硬件只是模型能力的展示载体。

不只做“大脑”,还把数据做成生意
王启斌将公司发展划分为三个阶段:硬件、数据、产品落地。目前,灵初智能正处于第二阶段——数据阶段。
在灵初智能看来,数据不仅是训练模型的“燃料”,本身也可以成为商业模式。目前,公司已开始向头部具身智能公司和基模公司供应人类视频数据及精细操作数据。“数据会成为基模公司和集成公司非常重要的输入。”王启斌表示。
但问题是,随着越来越多的公司开始自己采集人类数据,灵初智能对外供应数据的独特优势在哪里?王启斌认为,正是因为自己训练模型,公司才更深刻理解什么样的数据有价值、如何采集、如何处理。这种对模型的认知能力,是其作为基模公司的外部数据供应方的优势所在。
王启斌把灵初智能的数据商业路径拆成了三层。
第一层,卖工具。灵初自研的外骨骼手套,能把数据采集成本降到传统真机方案的十分之一。这套硬件本身就是商品,可以卖,也可以租。

第二层,卖数据。灵初积累了近10万小时的人类操作数据,覆盖294种场景、4821种任务、1382种物体。王启斌说,灵初正在向这些客户供应数据。
第三层,卖方案。灵初提供的是“模型+灵巧手+数据服务”的整体打包。目前核心客户集中在两类场景:制造业的精密装配,比如电子产品组装;物流行业的服装仓储拣选、分拨和打包。
上述商业模式能否跑通,关键在于数据飞轮是否真的转起来——即每部署一个新场景,消耗的数据越来越少,积累的数据越来越多。从目前进展来看,灵初智能的具身模型已经验证了这一趋势:半年前,在物流场景部署一个新任务,需要消费几百条真机演示,而现在不到100条就能完成。
基于对技术周期的判断,灵初智能认为,具身智能的竞争已经深入到了“数据浪潮”的下半场。现在的核心不再是争论真机还是仿真,而是比拼谁能用数据真正驱动具身大脑在实际中落地。
灵初智能从数据定义权出发,走出了自己的节奏。在如何让数据产生商业价值、如何用数据支撑模型训练与产品落地的闭环上,他找到了可执行的路径。这正是灵初智能在具身智能下半场最核心的竞争力,也是其最坚实的商业护城河。
本文为创业邦原创,未经授权不得转载,否则创业邦将保留向其追究法律责任的权利。如需转载或有任何疑问,请联系editor@cyzone.cn。







