
为什么机器人学习人的动作这么难?答案其实藏在操作失误后的学习中。
以倒水为例。水快倒满的时候,人会本能把手腕压低,如果没控制住压多的话,就会让上升的水面晃起来,甚至溅出水。发现情况后,人就会谨慎:视线盯住杯口,手腕角度放缓,把倒水速度降下来。再倒第二杯时,人会根据刚刚的失误调整了动作。
这个变化很小。放在视频里,可能只是几帧动作差异;放在力反馈手套里,也许只是手部姿态和受力波动。但人已经完成了一次学习——因为一次错误,改变了下一次操作。
具身智能里真正难的Self-Evolution(自我进化),常常就藏在这种细节反馈中。
它不是在既定轨迹上重复执行,而是在真实世界中,系统试一次,错一点,意识到不对,再把下一次做得更好。相比模型在文本里自己生成题目、自己打分、自己改答案,或者机器人在仿真里重复刷轨迹,真实操作里的自我进化更细碎,也更难被完整记录。
这些细节数据,是被大量具身数据忽略的中间层,也是一家叫脸谱心智的初创公司的切入点。
错误发生之后,人到底如何更新自己的操作策略?

Self-Evolution到了真实世界
第一关就是“知道自己错了”
现在谈Self-Evolution,很多讨论还停留在模型内部:模型生成答案,评估器给反馈,再让模型修正;模型生成代码,跑测试,报错,再改;模型生成任务,筛掉坏样本,再继续训练。
这套逻辑在数字世界更容易成立。因为错误通常有明确形式:测试没过、答案不一致、工具调用失败、评分低于阈值。
但在物理世界,就并不是那么简单了。真实世界里的错误没有统一的红色报错,更多的错误表现为杯子倾斜过了一点、物体快从指尖滑掉、手臂轨迹偏了几厘米、夹取点没有对准,或者力道再大一点就会压坏物体。
这些错误往往发生在“彻底失败”之前。
人之所以能及时调整,是因为人不会等结果坏掉后才学习。很多时候,眼睛已经捕捉到偏差,注意力开始转移,手上的力度和角度也跟着变了。
这是人类真实操作里的自我进化:失败复盘之外,还有大量毫秒级反馈里的边做边改。

现有数据大多只拍到了“动作”
没拍到“学会”
过去具身智能补数据,最常见的办法是采视频、轨迹、手套、力反馈。这些数据当然有用:视频能告诉模型人当时看到了什么,轨迹能告诉模型手怎么移动,力反馈能告诉模型接触发生在哪里,手套能告诉模型手指弯曲和抓握状态如何变化。
但问题在于,这些信号更擅长记录外部结果,不擅长记录内部更新。
比如一个人第一次倒水洒了,第二次没洒。视频可以看到第二次更稳了,手套可以看到手腕控制变了,力反馈可以看到动作幅度变小了。但模型很难仅凭这些外部信号判断:这次变化是随机动作差异,还是因为上一次水洒了以后,人已经更新了策略?
更难知道的是,人是什么时候发现“不对劲”的,注意力为什么突然转向杯口,手部动作为什么提前放缓,下一次为什么会主动避开同一个风险点。
现有数据经常能记录“人改了动作”,但不一定能记录“人为什么开始改”。Self-Evolution最关键的,恰恰是后者。

从世界模型
到人类试错数据
脸谱心智 由两位95后博士陆弘远和韦怡然创立。他们早期从端侧全模态模型切入,随后将重心转向更底层的世界模型研究。
在模型侧,他们最近提出了LoopWM( Looped World Models) 。按照论文中的说法,LoopWM试图把loop引入世界模型架构层面,通过参数共享的transformer block,对latent state进行迭代式refinement,让模型在隐藏状态中多轮滚动、修正,逼近更稳定的状态理解。
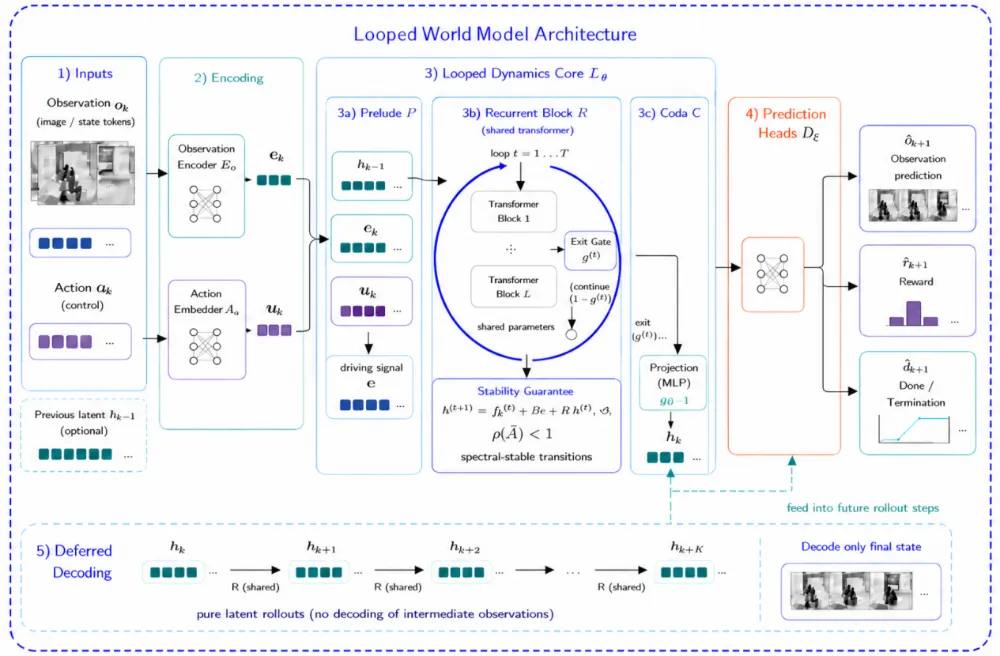
论文链接:https://arxiv.org/abs/2606.18208
这自然带出另一个问题:如果模型架构可以通过反复修正来提升对世界的理解,那么数据侧也需要一种更适合“自我修正”的训练材料。
今天大多数ego-centric、human-centric数据,仍然主要记录人看到了什么、手做了什么、任务有没有完成。这些数据,能覆盖大量真实场景,也能提供丰富的人类操作样本,但对于“动作为什么会改变”这件事,记录得还不够完整。
一次操作从画面到结果之间,还包括目标锁定、动作准备、意图形成、肌肉执行、错误感知和实时修正。如果这些过程没有被记录下来,模型学到的就更接近动作结果或行为轨迹;如果这些过程能被同步采集、对齐并结构化,模型才有机会学习动作背后的自我更新机制。
于是,问题从模型架构走向数据范式:在现有第一视角视频和人类操作数据之外,能不能进一步采到“错误如何改变下一次动作”的过程数据?
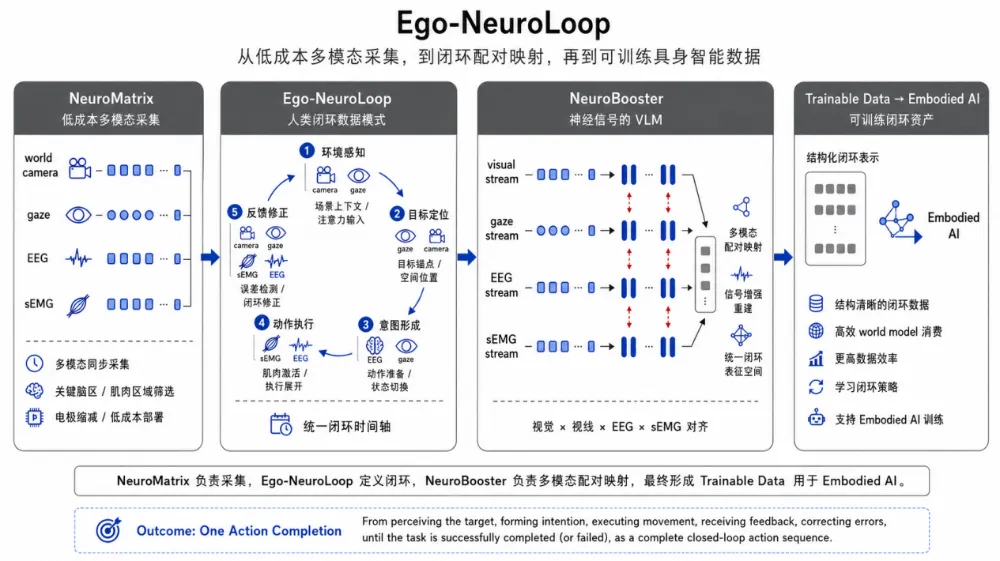
脸谱心智给出的答案,就是Ego-NeuroLoop。

Ego-NeuroLoop:
把人类的试错过程,变成可训练数据
Ego-NeuroLoop可以拆成三个关键词:Ego是第一视角,记录人站在任务现场到底看到了什么、关注了什么、如何理解环境;Neuro是神经与生理反馈,记录错误识别、动作准备、状态切换、注意力变化这些更靠近内部策略更新的信号;Loop则是闭环,关注一次尝试如何影响下一次尝试。
Ego-NeuroLoop真正关心的并非“这一杯水有没有倒好”这个结果,而是更细的过程——第一次为什么洒了,洒出来的瞬间人有没有察觉,视线随后看向哪里,手部肌肉控制发生了什么变化,第二次倒水之前人的动作策略是否已经改变。
这类数据记录的是“人如何在错误中更新自己”。它即学习成功动作,也学习人类如何从不完美动作里提取下一次做得更好的动作。

脑电信号的价值:
给“意识到错误”打上时间戳
这里最容易被低估的一层,是EEG等神经层信号。因为在很多数据采集方案里,脑电不如视频直观,也不如力反馈手套那样容易解释。但如果目标是让机器人学会Self-Evolution,脑电的价值会变得非常明确:人在什么时候发现动作偏了、需要调整了。
人脑在遭遇错误、冲突或偏差时,大脑会出现相对错误的脑电反应。它不能被简单理解成“读心”,也不能直接解读人的完整意图解析,却能提供一个纯视频很难提供的信息:这个人是否在某个时刻检测到了不对劲。
这一点很关键,因为外部动作发生变化,往往已经是后面的结果。更早的链条可能是脑中先出现错误监控信号,随后注意力转向风险点,再随后肌肉发力模式改变,最后才体现在外部动作。
如果只采视频,模型看到的是最后一步;如果加入gaze、sEMG、EEG等同步信号,模型才有机会看到整个过程:人是在检测到错误之后,把下一次操作重新组织了一遍。

NeuroMatrix:
为Ego-NeuroLoop设计的采集矩阵
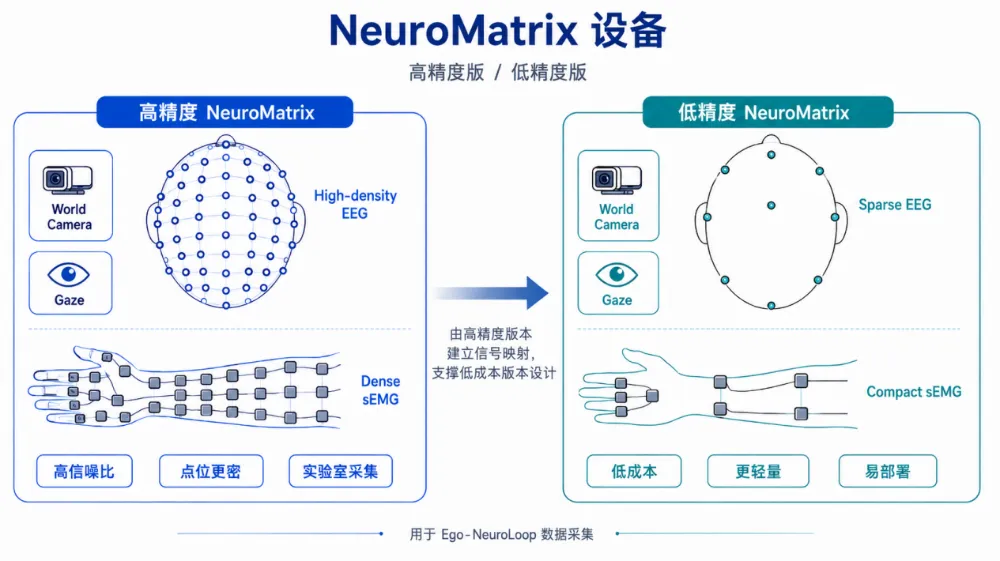
为了采到这种数据,脸谱心智做了采集装置NeuroMatrix。它是一套围绕Ego-NeuroLoop数据范式设计的采集矩阵,目标是在同一时间轴上记录第一视角、视线、肌肉执行和神经反馈。
不同信号负责不同问题:第一视角视频回答当时世界是什么样,gaze回答人真正盯住了哪里,sEMG回答肌肉如何准备和执行动作,EEG等神经层信号回答错误、冲突、状态切换是否已经被检测到。只有把这些信号对齐,放到同一条时间轴上,才可能还原一次真实的操作更新。
以倒水为例,视频看到水面开始晃动,EEG捕捉到错误或冲突相关反馈,gaze显示视线转向杯口和水面,sEMG显示手腕和手指的控制模式改变。下一次倒水时,视线提前落到风险点,动作也变慢、变稳。此时,数据样本就不再停留在“人倒水”,而是进一步记录“人如何因为上一次水洒了,改变下一次倒水”。
NeuroMatrix的成本逻辑,也不是简单把传感器堆到最便宜。更合理的路径,是先用高精度版本采集一批足够干净、足够完整的EEG、sEMG、gaze和第一视角数据,建立人类动作意图、错误反馈、肌肉执行和视觉目标之间的高质量对应关系。再用低成本版本采同类任务,把高精度信号和低精度信号进行配对训练,让模型学会从低成本、低信噪比的数据里还原关键闭环语义。
这样一来,硬件设计就可以围绕“最有信息量的位置”收缩。比如,在高精度采集阶段找到与手臂、手指动作高度相关的脑电通道、头皮电极位置和肌肉区域之后,低成本设备就不需要完整复刻实验室级配置,而可以减少电极数量、压缩传感器点位、降低佩戴复杂度,把采集装置做成更轻、更便宜、更容易部署的形态。
机器人Self-Evolution需要大量真实场景下的试错过程,而非少数昂贵样本。倒水、开门、插线、拧盖、切菜、拿杯子、整理桌面,每个动作里都有大量微小偏差,也都有大量策略更新。只有采集系统足够轻、足够便宜、足够可部署,这些日常操作中的微小进化才可能变成可用数据。

NeuroBooster:
把低精度信号补成可用闭环数据
多模态信号采上来,只是第一步。
真实世界里的低成本采集,天然会带来噪声:EEG可能受到电极接触、头动伪迹和眨眼影响,sEMG可能受到佩戴位置偏移、肌肉串扰和动作噪声影响,gaze数据可能漂移或短时丢失,视觉数据也可能出现遮挡、模糊和视角变化。
这也是NeuroBooster要解决的问题。
如果说VLM把图像和文本映射到统一表征空间里,让模型理解“一张图对应什么语义”,那么NeuroBooster要做的,就是把视觉、视线、EEG、sEMG映射到统一闭环表征空间里,让模型理解一个动作如何从目标、意图、执行到反馈修正一步步生成。
更关键的是,NeuroBooster承担了“高精度到低精度”的转换任务。高精度采集版本相当于老师,提供更完整、更清晰的人类闭环信号;低成本采集版本相当于学生,记录更粗糙、更嘈杂、但更容易规模化的数据。通过高低精度版本的配对训练,NeuroBooster可以学习两类信号之间的对应关系,把低成本设备采到的弱信号、缺失信号和不同步信号,补成更稳定的Ego-NeuroLoop表征。
这一步的价值在于利用多模态之间的互补关系做增强重建:当EEG信号较弱时,sEMG和gaze可以补充动作执行与目标信息;当sEMG存在噪声时,视觉和EEG可以提供动作阶段和意图线索;当gaze漂移时,world camera和动作状态可以帮助恢复目标上下文;当某一路信号短时缺失时,其他模态也能提供时间线索,帮助模型维持闭环结构。
最终,模型看到的是一条经过同步、对齐、配对映射、信号增强和结构化处理的闭环时间轴:环境里有什么,目标在哪里,错误何时被检测到,注意力如何变化,肌肉如何响应,动作如何修正,下一次尝试为什么会不同。
这才是Ego-NeuroLoop真正想提供给具身智能模型的东西。

从行为模仿,到错误驱动学习
具身智能当然需要成功示范。但只看成功示范,模型看到的是结果最顺的一面。它不知道人类在学会这个动作之前经历了哪些微小偏差,也不知道哪些风险点需要提前注意,更不知道失败苗头出现时应该如何调整。
真实世界里,成功动作往往是被大量小错误“雕刻”出来的:第一次没夹住,第二次手指收紧;第一次杯子碰到桌沿,第二次路径绕开;第一次水洒出来,第二次倒得更慢;第一次插头没对准,第二次先调整角度。这些变化不一定能形成一个明显的失败标签,但学习恰恰发生在这里。
所以Ego-NeuroLoop想采的数据,是从 demonstrations(演示) 进一步走向corrections(修正);是从“人类完成任务的样子”,走向“人类变得更会完成任务的过程”。这会把数据重点从action(动作) 拉向correction(修正),从单次轨迹拉向多次尝试之间的差异,从成功结果拉向错误反馈后的策略更新。

模型要学的
是“下一次怎么不同”
到这里,Ego-NeuroLoop、NeuroMatrix、NeuroBooster和LoopWM就可以自然连起来:NeuroMatrix 负责把人类真实操作中的试错过程采下来,NeuroBooster负责把多模态原始信号整理成可训练数据,Ego-NeuroLoop定义了这种数据到底要表达什么,而LoopWM则尝试让 世界模型学会“错误之后,人是如何调整下一次动作的”。
放到具身场景里,训练目标也会随之变化。过去更常见的问题是:给定当前画面,预测人手下一步会去哪里。现在更值得追问的是:给定上一次偏差和错误反馈,下一次操作会发生什么变化。
最终目标是让机器人学会像人类一样:第一遍不够好,第二遍就该不一样。

最后
具身智能的Self-Evolution,不会只靠更多成功视频解决。
因为真实世界里的进步,常常来自一次很小的错误以及错误之后的调整。水洒了一点、手滑了一下、夹空了一次、碰偏了一点、力度大了一点,这些瞬间看起来不起眼,但会改变人的下一次动作。
过去的数据采集,更多记录了动作本身。脸谱心智想补上的,是动作改变背后的那条链路:错误如何被检测到,注意力如何被重新分配,肌肉控制如何被修正,下一次尝试如何因此变得不同。
Ego-NeuroLoop对应的采集和建模体系围绕人类闭环操作展开;NeuroMatrix先用高精度采集建立信号地图,再把硬件收缩到低成本、可规模化版本;NeuroBooster则通过高低精度配对训练,把低成本设备采到的粗糙信号补成可用的闭环表征。
最终,这些数据可以进入LoopWM这样的世界模型,帮助模型学习真实世界中的错误反馈和策略更新。
它们最终指向一个更关键的问题:
机器人如果真的要自我进化,就必须先看懂人类是怎样在错误之后变得更好的。







