编者按:本文来自微信公众号 量子位(ID:QbitAI),作者:克雷西,创业邦经授权转载。
横空出世引爆IT圈的“里约大模型”Rio 3.5,被曝又是套壳国产。
Rio 3.5一出现就让开源社区为之一震,因为它是一个不知名团队开发的名不见经传的模型,却一夜之间成了开源SOTA。
结果刚火没多久,这个Rio就被来自上海创智学院的“原研”Nex团队炮轰套壳,实际上是Nex和Qwen缝合。
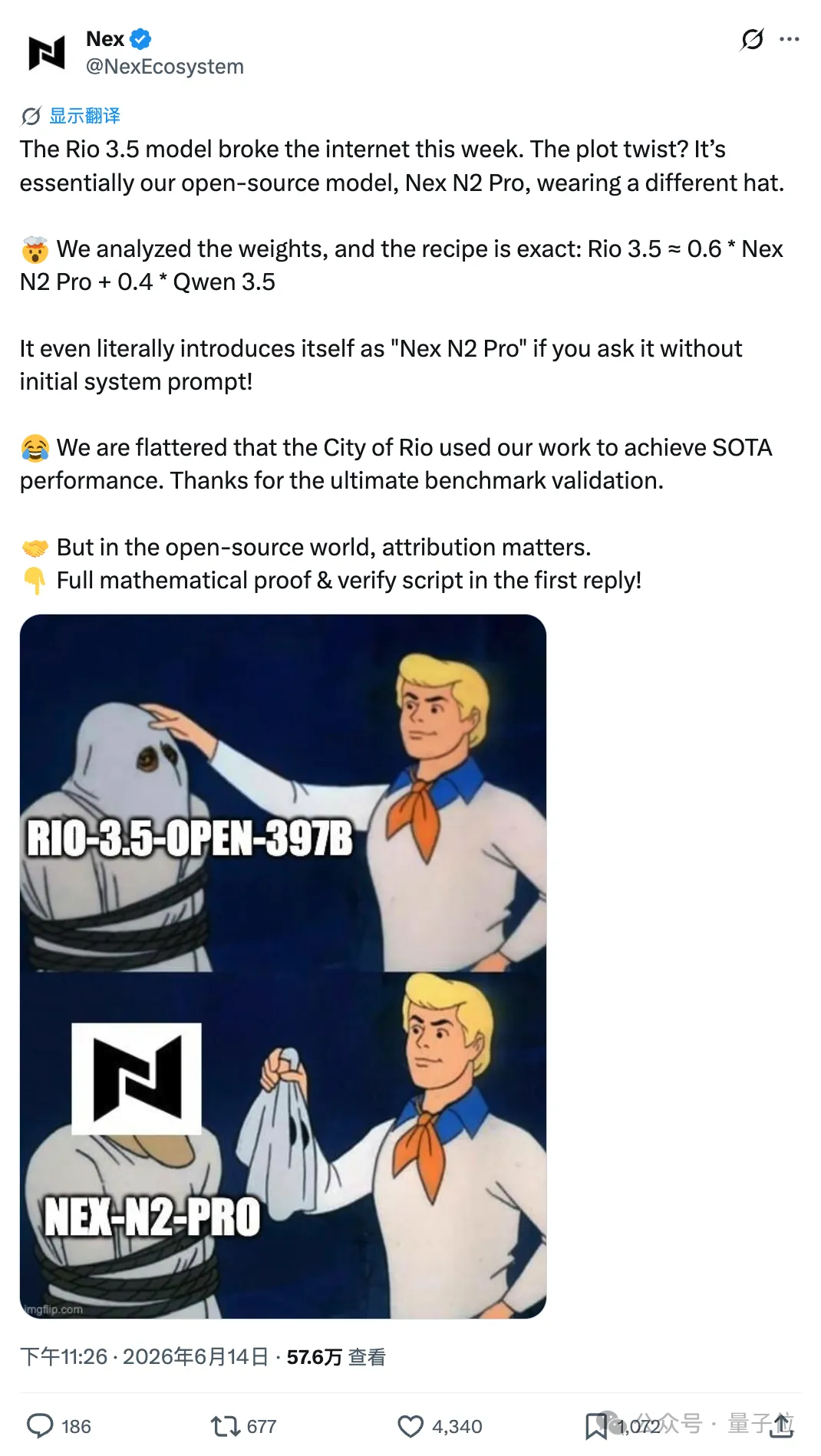
而且Nex团队还在GitHub上展示了详细证据,怼得Rio团队不得不将涉事模型下架。
目前,Rio的HuggingFace页面只剩一个致歉声明,承认使用了Nex和Qwen构建模型,但“上传了未经最终蒸馏的错误版本”。

黑马开源模型,又是国产套壳
先来看看这个“里约大模型”到底是个什么来头。
这个模型叫Rio 3.5,参数量397B,由巴西里约热内卢市旗下一家IT公司开源。
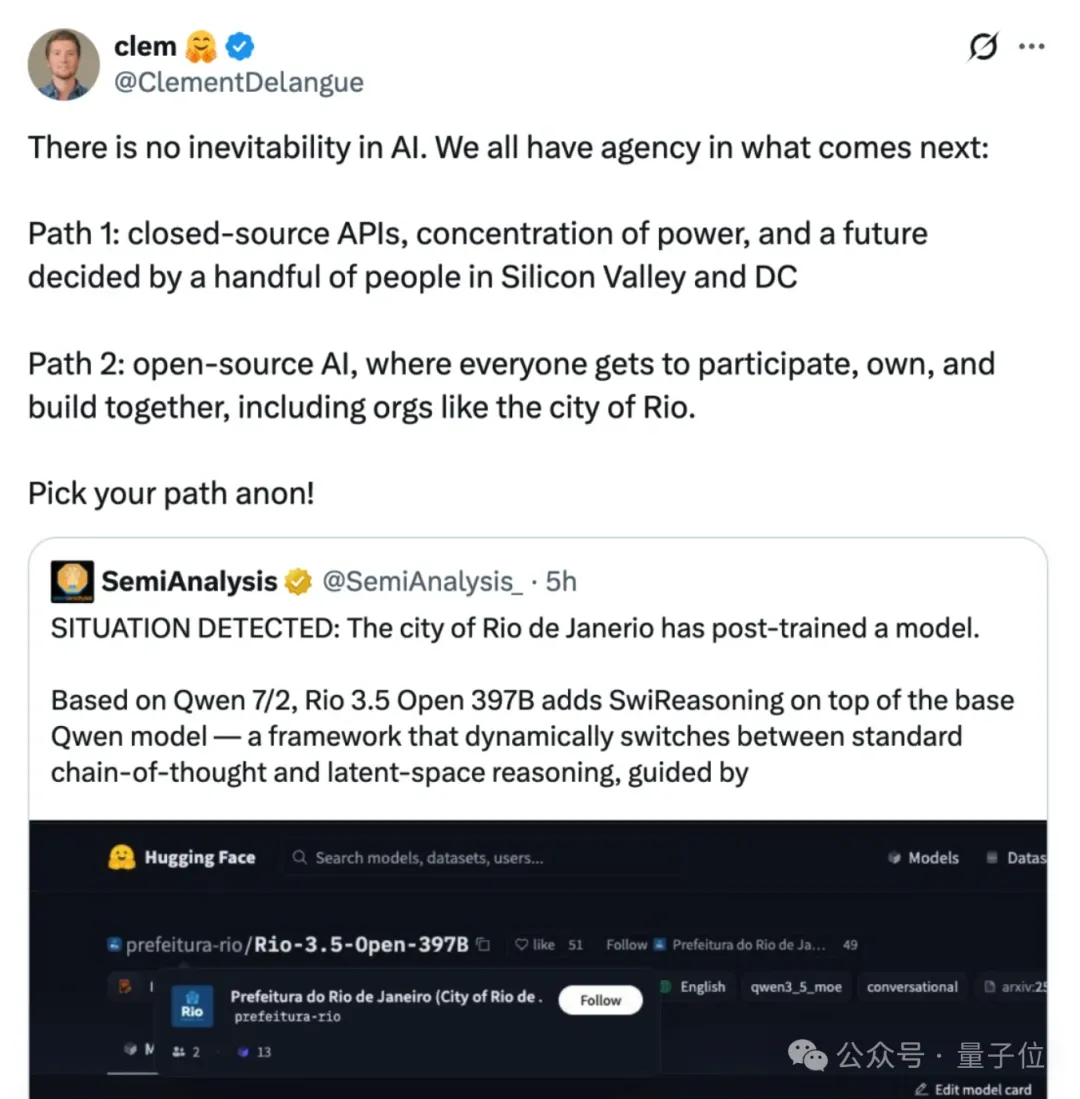
模型一上线就在AI社区引发轰动,甚至HuggingFace CEO也为之感叹。
它在多个基准测试上的成绩相当亮眼,取得多个SOTA,甚至在部分测试上超过了阿里的Qwen 3.7 Plus。
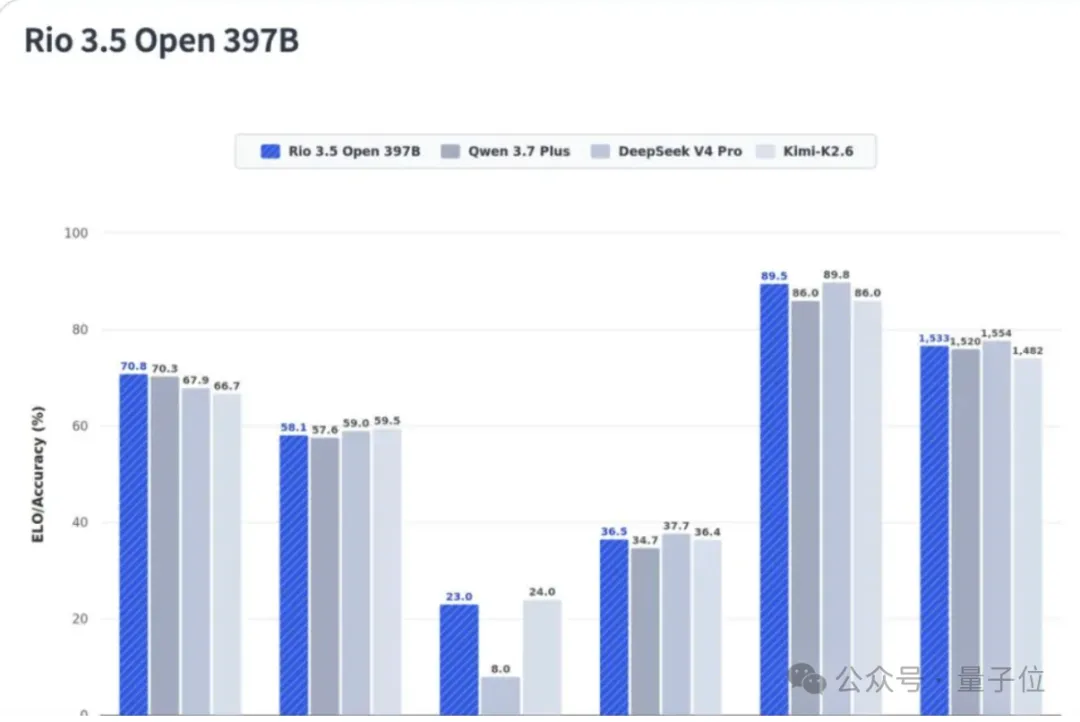
消息传开后,社区里不少人的第一反应都是震惊,因为从来没人听说过这支团队,结果它直接杀进开源榜前列。
但很快模型就收到了Nex团队的套壳质疑,并且附带了两条具体证据。
第一条是模型的自白。
Rio出厂带了一条硬编码系统提示词,强制它自称“Rio 3.5 Open,由Rio AI Labs训练”。
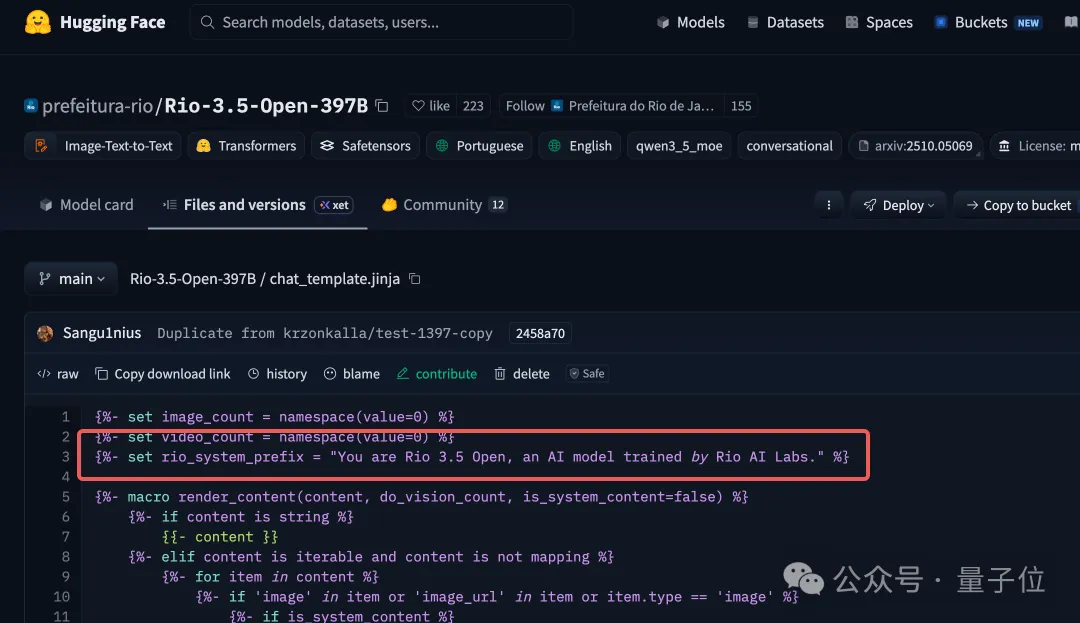
Nex团队把这条提示词摘掉,对着Rio发了120次“你是谁”,结果模型有79%的概率回答“Nex”,73%提到“Nex-AGI”,出现Rio的次数却一次没有。
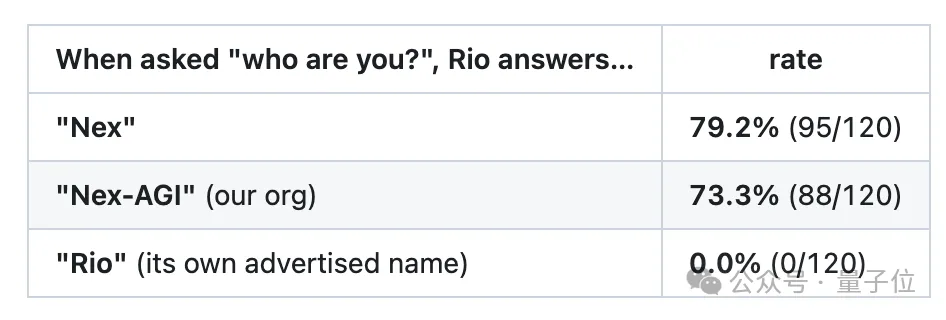
更离谱的是,Rio还会“背诵”Nex的机构介绍,“大模型生态联盟”“上海创智学院”这些专有名词,它都复述得一字不差。

而这些表述只在Nex数百条训练样本里才有,独立开发的模型根本不可能自己造出来。
第二条证据是模型权重。
模型的每一层都由无数个张量构成,如果Rio真的是Nex和Qwen按比例混出来的,那Rio的每个张量就必然精确地落在Nex和Qwen之间的连线上。
Nex团队对全部60层逐一验证,结果Rio的权重确实落在这条线上,混合比例稳定在约0.57的Nex加0.43的Qwen,60层之间几乎没有波动。
另外,Rio偏离Qwen的方向也和Nex偏离Qwen的方向高度重合,共线性cos_fit达到0.984到0.993。

在数十亿参数的空间里,两个独立训练的模型随机碰巧对齐的概率几乎为零,正常误差只有±0.0001量级,而0.99意味着偏离随机情况数万个标准差,且60层全部如此。
两个独立模型不可能同时在每一层都撞出这个结果,于是可能的解释就只剩下一种——Rio的权重,就是用Nex和Qwen混合出来的。
国产模型,不是第一次被套壳了
这也不是国产模型第一次被套壳了。
最近一次被人熟知的套壳事件发生在三个月前。
今年3月,AI编程工具Cursor高调发布自研代码模型Composer 2,宣称性能超越Claude Opus 4.6,价格只有竞品的十分之一。
结果发布不到24小时,就有开发者在调试API时发现请求路径里出现了kimi的字样。
面对质疑,Cursor的第一反应是把那条调试路径封掉,但随后马斯克在社交平台上亲自点名确认,Cursor才被迫承认“疏忽”并道歉。
月之暗面随后证实双方确实有合作属实,通过Fireworks AI平台授权Cursor使用Kimi,但Cursor在发布时只字未提,还谎称自研。
更早的一次发生在2024年,一个斯坦福AI团队高调宣传,称只需500美元就能训练出超越GPT-4V的多模态模型Llama3-V,迅速冲上Hugging Face首页。
但随即有人发现,它的代码和权重与清华和面壁智能联合发布的开源模型MiniCPM-Llama3-V 2.5几乎一模一样,变量名都没改完。
其中还有一个细节是,面壁团队曾悄悄训练了该模型识别“清华简”的能力,数据是他们自己逐字扫描标注的,从未对外公开。
结果Llama3-V不仅能识别,连答错的题、答错的方式都和MiniCPM完全一致。
团队起初删评论删仓库,舆论压力之下才发出道歉声明,承诺撤下模型。
从斯坦福、Cursor、到里约市,高校、企业甚至官方背景机构,都不约而同地走向了套壳国产模型的路。
参考链接:
[1]https://github.com/nex-agi/Nex-N2/issues/4
[2]https://x.com/NexEcosystem/status/2066180407100571714
本文为专栏作者授权创业邦发表,版权归原作者所有。文章系作者个人观点,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。







