编者按:本文来自微信公众号 刘润(ID:runliu-pub),作者:景九,编辑:歌平,创业邦经授权转载。
人类又一次,把AI的话当真了。
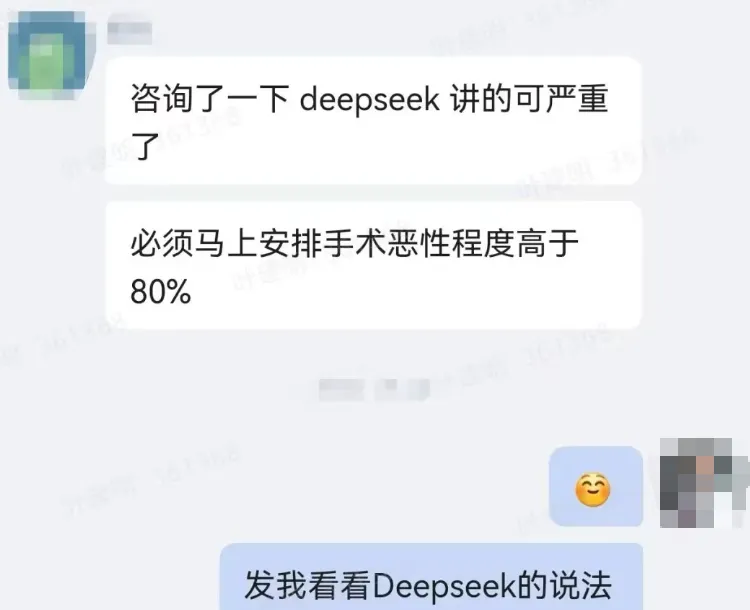
这两年,“被AI坑”已经不新鲜了。有人用 ChatGPT 写法律文件,结果判例是假的,比如“Varghese诉中国南方航空” 。有人用DeepSeek做健康咨询、结果得到了“80%是肺癌”的结论,吓得不轻。
但这次,情况似乎更严重了。
有人在小区发现一种蘑菇,拍了照片,问豆包:这能不能吃?豆包说,这个东西“可能是鸡腿菇”。可以吃。可豆包也补充,“它容易和大青褶伞混淆,误食会引发胃肠炎症状”。所以,如果是从外边采来的,不要吃。
你看,豆包不是没有提醒。它没有斩钉截铁地说:放心吃。它说了“可能”,也说了“外边采来的建议不要吃”。
可用户还是吃了。然后,上吐下泻。
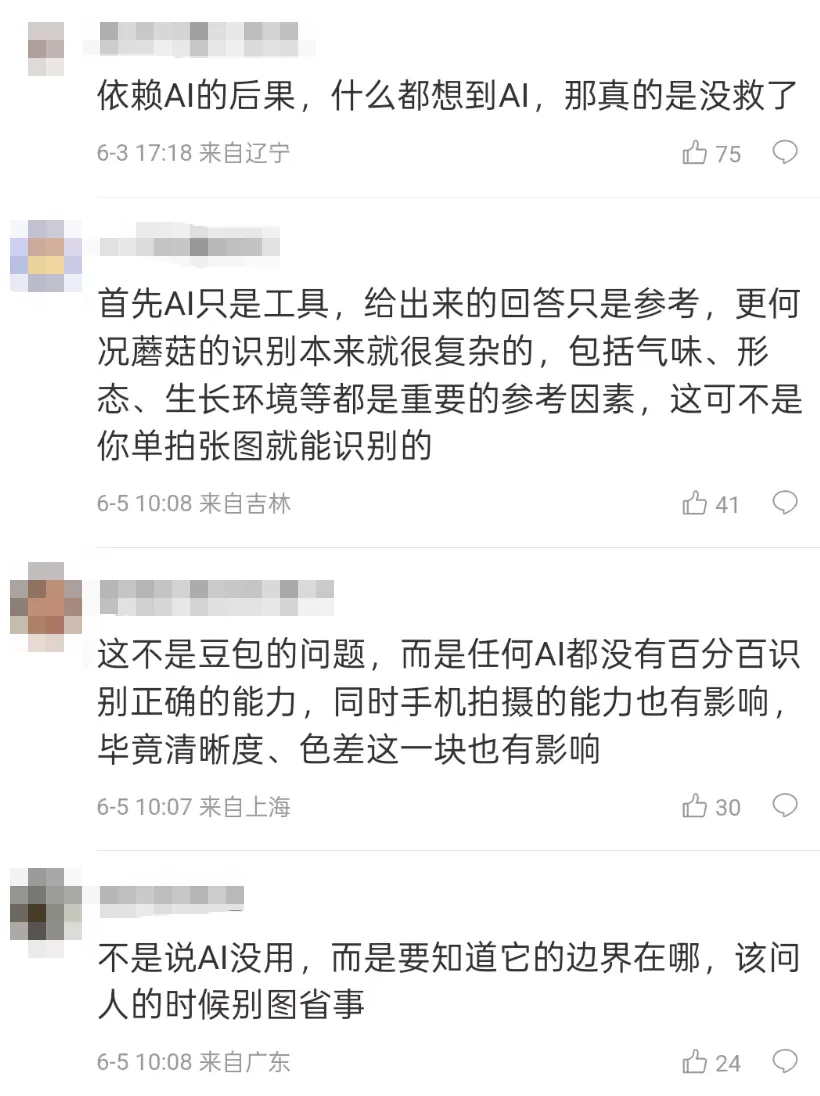
于是,很快有人评论:
这能怪谁?人家明明提醒你了。野蘑菇不能乱吃,这不是常识吗?你自己不知道边界,把AI当专家,中毒不是活该吗?
(图片来自微博)
说用户本人没有责任,当然不对。野蘑菇不能乱吃,AI回答不能当食品安全依据,豆包也确实加了提醒。
可用户有责任,不等于AI大模型没有责任。当答案可能影响人的安危时,如果AI并不确定,还应不应该回答?
这个问题,在机器学习领域,其实早就被讨论过了。
有个说法,叫:拒绝选项(Reject Option)。
1970年前后,C. K. Chow就在论文中提出了“拒绝选项”,意思是分类器遇到把握不足的样本时,应当拒绝判断,将处理权交给人或其他系统。
为什么?因为有些问题,答错的代价太大了。
比如问AI,穿啥颜色的衣服?它答错了,最多就是你心情差点。可你问AI,这个蘑菇能不能吃?它答错了,你就可能中毒,可能去医院抢救。
这时候,不回答就是更安全的输出。
2017年,计算机科学家Geifman提出:机器学习里一种最基础的“自知之明”,就是知道自己不知道。比如自动驾驶。如果路况实在复杂,理想状态不是硬开,而是把控制权交给人。
可是,既然不确定时拒答更安全,为什么大模型还总想回答?
这就和它的商业目标,有关了。
今天,能稳定盈利的大模型公司并不多。可是怎么变现?怎么收费?还没有一个公认的答案。所以才有这么一个共识:我们先把用户规模养起来。
怎么养?先让自己,变得“有用”。
有用最直接的表现,就是你问什么,它都能接住。不仅接住,还要接得顺、接得让你愿意继续问。
你让它写段文案,它写。你让它做一个表格,它做。你问它一个概念,它解释。你问它怎么创业、怎么投资、怎么追女生、怎么教育孩子,它都能说上几句。耐心,热情,次次有回应。
所以,出于商业目的,AI大模型,会天然走向:尽量回答,努力讨好。
因为,如果你问蘑菇,它不能答。你问投资,它不能答。你问创业,你也一堆风险提示,那你很容易就换个愿意回答的AI。
可问题是,它越想回答,越容易产生幻觉。
幻觉,就是一本正经地胡说八道。你问它论文出处,它可能会给你作者名、年份、期刊,但你真去查,会发现根本不存在。
大模型的输出机制,是通过概率,猜下一个词。它会根据自己学过的内容、检索到的信息,判断接下来最应该出现什么词。这是统计意义的智能,而非人类意义的理解。这种机制,必然带来幻觉。
这件事,放在普通问题里,没什么。但在高风险问题上,就很要命。你问100次作者错10次,没关系。你问一次毒蘑菇,它错一次就出大事。
那,大模型公司知不知道这事?当然知道。但他们又很难冒着失去用户的风险,拒绝回答。所以只好:做免责声明。
最常见的办法,就是在回答后面加提醒:
大模型可能会犯错,请你自行判断。以上内容仅供参考,不构成专业建议。涉及医疗、法律、投资、食品安全等问题,请咨询专业人士。
尽量回答,努力讨好,常常幻觉,总是免责。
这就是今天多数大模型的表现。因为它想让你觉得它什么都能答,但又无法保证都对,所以只能再加一句:我不一定对,请自己判断。
可是,提醒存在,不等于有效。免责声明写了,不等于用户理解了。
为什么?首先,“免责声明”的边际效用,会越来越弱。
你第一次看到“大模型可能会犯错,请自行判断”,可能会想一想。可到了第一百次,一千次,你可能就略过了。就像安装软件时的“用户协议”,进网页时看到“风险声明”。它们都在,但你已经不读了。
一开始,风险提示是提醒用户的。后来,它越来越像保护平台的。
其次,机器给出的答案,人天然更容易相信。
当你听到导航说往左,你就往左。哪怕你隐约觉得不对。系统说这个客户风险低,你就放松警惕。系统都算过了,应该没事吧。AI说“这可能是鸡腿菇”,你也可能会想:它都看过那么多资料了,应该比我懂吧。
在心理学和人机交互里,这种倾向,叫做:自动化偏误。
意思是,人在与自动化系统(如AI、程序)协作时,很容易就过度依赖其输出,从而放弃独立思考,验证信息。
所以,用户看完一段AI回答,最容易记住的,往往不是最后那句“请自己判断”,而是前面的具体回答。
回到这次“蘑菇中毒事件”。
豆包做了很多事。它加了警告、点了具体毒蘑菇的名字、提示了胃肠炎症状。但如果在这些免责声明之前,它首先给出了“这可能是鸡腿菇”的判断,那无论免责声明写得多么严厉,都可能让用户放松警惕。
那怎么办?瞎说一个不负责任的建议:
再遇到类似的问题,或许可以把回答顺序倒一下。
先说“这个问题涉及食品安全,AI回答可能犯错,请勿据此食用”。再说“从图像特征看,它有一定可能是鸡腿菇,但也无法排除剧毒的大青褶伞”。
先给出的信息,更容易成为用户脑子里的锚。所以,先说“像鸡腿菇”还是先说“我说的可能不对”,可能截然不同。
我们正在进入一个,AI深度参与人类判断的时代。
过去很多技术革命,改变的是工具。车跑得更快了,机器算得更准了。但它们只是把能力交给你,最后怎么判断,还是你来。
但AI,不只是给你信息,它还会直接给你结论。该不该买股票?它给你分析。蘑菇能不能吃?它也会给你一个判断。
而一旦进入判断链条,它就不能只追求有问必答。
或许,高风险场景里,一个成熟AI最重要的能力,不是回答得越来越像专家。而是在没有把握的时候,敢于先说:
对不起,这个我不知道。

参考资料:
1、抖音副总裁回应“豆包误判蘑菇致用户中毒”
2、陈焕|GPT两周年-盘点那些使用AI生成内容被“公开处刑”的法律人
本文为专栏作者授权创业邦发表,版权归原作者所有。文章系作者个人观点,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。







